All 24 entries tagged Programming
View all 131 entries tagged Programming on Warwick Blogs | View entries tagged Programming at Technorati | There are no images tagged Programming on this blog
August 21, 2019
Fortran Memory Management II
Follow-up to Fortran Memory Management from Research Software Engineering at Warwick
This month we're going to cover the question of what to watch out for with using ALLOCATABLEs in Fortran.
Array bounds in functions
Fortran arrays have the very nice property that their indices don't have to run from any specific value to any specific value. So if you want an array that runs from -3 to 103 that's fine. You can allocate it as
INTEGER, DIMENSION(:), ALLOCATABLE :: array ALLOCATE(array(-3:103))
This maps quite neatly maps onto lots of scientific use cases so you quite often see arrays with explicit upper and lower bounds in real world Fortran codes. You can check the upper and lower bounds easily enough using the UBOUND and LBOUND functions
INTEGER, DIMENSION(:), ALLOCATABLE :: array ALLOCATE(array(-3:103)) PRINT *, LBOUND(array), UBOUND(array)
Produces the output "-3 103" as you'd expect. But there is a wrinkle. What if you move those calls to LBOUND and UBOUND into a function?
MODULE mdl
IMPLICIT NONE
CONTAINS
SUBROUTINE print_array(array)
INTEGER, DIMENSION(:), INTENT(IN) :: array
PRINT *, LBOUND(array), UBOUND(array)
END SUBROUTINE print_array
END MODULE mdl
PROGRAM p1
USE mdl
IMPLICIT NONE
INTEGER, DIMENSION(:), ALLOCATABLE :: array
ALLOCATE(array(-3:103))
CALL print_array(array)
END PROGRAM p1
The result now is "1 107". The same number of elements but the lower bound has been moved back to the Fortran default of 1. This is the default behaviour of Fortran when you pass an array into a function; the lower bound is reset to 1. You can override this behaviour to specify the lower bound of the array in the function (INTEGER, DIMENSION(-3:), INTENT(IN) :: array will specify that the lower bound is -3), you can even pass in a parameter to the function to specify what the lower bound is (simply pass in an integer parameter and use it in the DIMENSION option in the same way that I used -3 before) but you can't just use the lower bound that the array was given when it was created. However, if you flag the array argument to the function as either ALLOCATABLE or POINTER things are different.
MODULE mdl
IMPLICIT NONE
CONTAINS
SUBROUTINE print_array(array)
INTEGER, DIMENSION(:), ALLOCATABLE, INTENT(IN) :: array
PRINT *, LBOUND(array), UBOUND(array)
END SUBROUTINE print_array
END MODULE mdl
PROGRAM p1
USE mdl
IMPLICIT NONE
INTEGER, DIMENSION(:), ALLOCATABLE :: array
ALLOCATE(array(-3:103))
CALL print_array(array)
END PROGRAM p1
This version of the code looks almost identical but now reports the lower and upper bounds as -3 and 103. In fact, you now can't override the bounds of your array even if you wanted to (if you try putting the lower bound in the DIMENSION part of the parameter definition in the function the code will fail to compile). The main downside is that you now can only pass ALLOCATABLE arrays to the function because the main purpose of applying the ALLOCATABLE option to the parameter is to allow you to allocate and deallocate the array inside the function. The POINTER attribute works in much the same way but only for POINTER arrays
Mostly this sort of thing isn't too much of a problem but you do have to be careful. If you have a function that takes a normal non-ALLOCATABLE parameter then it's tempting to simply recognize that the array lower bound will start from 1 inside the function and write the function accordingly. The problem is that if you ever then have cause to add the ALLOCATABLE or POINTER attribute to the function then you'll have to completely rewrite the function because suddenly the lower bound is no longer under your control. It's generally a good idea to always specify the lower bound of an array argument to a function, either through a fixed value if it's always the same for all arrays that the function will be used on or by passing in the lower bound as a parameter to the function.
Automatic Reallocation
The fact that Fortran allows you to do whole array operations is another feature that makes it well suited to scientific programming but there are some features that can be mixed blessings. One feature that was added to Fortran 2003 is that if you do a whole array assignment to an allocatable array that is either not allocated or is allocated to be a different size than the source array then the array will be reallocated to match the size of the source. To give an example
PROGRAM p1 IMPLICIT NONE INTEGER, DIMENSION(:), ALLOCATABLE :: array INTEGER, DIMENSION(-3:103) :: src array = src PRINT *, LBOUND(array), UBOUND(array) END PROGRAM p1
This program always feels like it's invalid but from Fortran 2003 onwards it is completely valid and will give you lower bound of -3 and upper bound of 103 because "array" is automatically allocated when "src" is assigned to it. In this example "array" is not allocated before I used it but if it was then it would have been silently deallocated and reallocated to the new size. This is quite useful for many purposes, it allows you to return an array from a function and just store it in an allocatable array and have everything magically work, and sometimes you do want to do literally what I'm doing in this example and make a copy of an array. Why would this ever be a disadvantage? Because it can make debugging much harder by moving the place where the bug occurs. Imagine the following situation
PROGRAM p1
IMPLICIT NONE
INTEGER, DIMENSION(:), ALLOCATABLE :: array1, array2
INTEGER :: i
!The incorrect allocation of array2 is a typo
ALLOCATE(array1(-3:103), array2(-2:103))
array2 = 1
array1 = 5 * array2
DO i = -2, 103
array1(i) = array(i) - array(i-1)
END DO
END PROGRAM p1
This program does nothing even remotely useful but it has the same structure as a real program that I had a problem with. There was an error in the size of an array that was then used in an array assignment. The assignment caused a reallocation of "array1" then then meant that the later loop was iterating over more items than the array now had so it crashed during the operation of that loop. Specifically the first iteration of the loop is trying to access the -3 element that now no longer exists. The loop in fact was perfectly well written for how the code should have been working but due to the error in the allocation of array2 the code was now crashing there. Without the implicit reallocation the error could have much more easily been traced to the array assignment (that in the real code was much further away from the crash site than in this simple example). There are a surprising number of ways of tripping this behaviour and causing errors in unrelated parts of your code because of this behaviour so if you get very unexpected array behaviour you should watch out for this one.
A question that then quite often comes up is if you can suppress this behaviour if you don't want it, and you definitely can. Most compilers have an option to disable the behaviour entirely (-fno-realloc-lhs in gfortran for example) and equally assigning to an array sectiondoesn't trigger the behaviour so
PROGRAM p1 IMPLICIT NONE INTEGER, DIMENSION(:), ALLOCATABLE :: array INTEGER, DIMENSION(-3:103) :: src array(:) = src PRINT *, LBOUND(array), UBOUND(array) END PROGRAM p1
will crash because you are assigning to an unallocated array. Some people say that from F2003 onwards you should probably always do array assignment to an array section if you don't want to invoke the automatic reallocation behaviour. I wouldn't go quite that far but you should definitely consider the question of if any odd bugs that you have are related to the automatic reallocation behaviour
 Christopher Brady
21 Aug 2019 18:15
|
Christopher Brady
21 Aug 2019 18:15
| ![]() Tags: Fortran Memorymanagement Programming
|
Tags: Fortran Memorymanagement Programming
|  Comments (0)
|
Comments (0)
|  Report a problem
Report a problem
 Please wait - comments are loading
Please wait - comments are loading
August 07, 2019
Fortran Memory Management
Memory Managment
Manually Managing
Memory management is one of the banes of the programmer's life in almost all programming languages. In many languages, such as C, you have to manually pair up all allocations of memory with associated deallocations or you will "leak" memory as your program runs. (Strictly a "memory leak" is when you create memory that you then lose track of in some way, so that you can't then deallocate it even if you want to. From the perspective of your program crashing when you run out of memory there's no difference between a true leak and just piling up unused but technically available memory somewhere so I tend to use the term a bit loosely).
Collecting the Garbage
Other languages, like Java, use mechanisms for counting how many times you use an item and when the last reference to an item is removed then the item will be deleted by something that is generally called a "garbage collector". The problem with these languages is that the garbage collector runs only periodically, not every time an item has its last reference released, so memory use can increase due to items that will be deleted when the garbage collector next runs but haven't been deleted yet.
Destructive Magic
Still other languages like C++ use objects that have systems of constructor and destructor functions that create memory when an object is created and release the memory when the object is deleted. This doesn't immediately sound like it's very helpful because surely that's still just a different way of saying that you have to have matched allocation and deallocation logic? The advantage comes from the fact that simple variables (like integers, floats etc.) don't have these memory management problems, the compiler automatically knows the lifetimes of these variables: they're either global variables the exist for the entire time that the code runs or they are local to a function and exist only when you are in that function (or in other functions called from that function etc.).
So long as you are dealing with a single instance of a C++ class and not a pointer to one or more of them then the compiler has the same level of lifetime guarantee that it has with the simple variables, and so long as the class knows how to allocate its memory when it is created (constructor function) and deallocate its memory when the compiler decides that it is finished with (destructor function) you don't have to worry about matching every single creation of the object with a matching destruction, you simply create them when you want them and let the compiler get rid of them when you are finished with them. To be strictly correct, modern C++ actually recommends against a developer doing memory management at all and recommends using STL containers to hold your data (which do the memory management themselves internally and have correctly implemented constructors and destructors). It really is a good idea to do this but scientific and research codes quite often find the odd edge cases where manually allocating and deallocating memory is the easiest solution.
Getting it for Free (Fortran Rules, OK?)
Since mostly in academic programming we tend to be working with arrays, C++ style objects are a fairly heavyweight way of dealing with problems of allocating and deallocating memory. It feels like it should be possible to have the same advantage of simply allocating an array when you need one but keep the advantage of allowing the compiler to automatically infer the lifetime of the variable and deallocate it when the lifetime is over without needing to go to a fully garbage collected model. In C that isn't really possible because arrays are mostly just pointers and the compiler can't be sure that a pointer is the only pointer to a block of memory. Programming would be impossible if your memory was deallocated as soon as any pointer to that memory went out of scope! But in more restrictive languages it is possible and fortunately Fortran is one of the languages that does have an option to do exactly that, and it's probably a feature of the language that you are already familiar with : the humble ALLOCATABLE array.
Allocatable Arrays in Fortran
Fortran allocatable arrays are very easy to use and anyone working in modern Fortran is probably familiar with them, but their properties are often not so well understood. For example to someone with a C background it feels as though this function should leak memory badly.
SUBROUTINE alloc_fn(els)
INTEGER, INTENT(IN) :: els
INTEGER, DIMENSION(:), ALLOCATABLE :: array
ALLOCATE(array(els))
END SUBROUTINE alloc_fn
but it actually doesn't leak any memory at all (although it equally doesn't do anything useful here). It also doesn't crash because you are trying to reallocate an already allocated array. The Fortran standard requires that when an allocatable array goes out of scope it should be deallocated, so that function will run allocate the array as requested and then deallocate it again as soon as the function is over. One question that you might then ask is "What about if I did want the array to stick around?", and as usual in Fortran that is possible by using the SAVE attribute to the array
SUBROUTINE alloc_fn(els)
INTEGER, INTENT(IN) :: els
INTEGER, DIMENSION(:), ALLOCATABLE, SAVE :: array
IF (.NOT. ALLOCATED(array)) ALLOCATE(array(els))
END SUBROUTINE alloc_fn
You'll notice that this time I've had to test if the array is allocated because otherwise I would wind up trying to allocate it twice and that will cause a runtime error. That is actually another nice feature of Fortran allocatable arrays that protects you from getting a common way of getting a memory leak in C - you cannot allocate an already allocated allocatable array. You can deallocate memory using a DEALLOCATE(array) statement and this can be useful if you want to explicitly manage the lifetime of your memory, for example if you have large intermediate arrays in a calculation that you don't want to have hanging around while you allocate other intermediate arrays. Many style guides do recommend manually deallocating memory on leaving a function, but that's mainly just a combination of caution and working round (mostly very old) broken compilers that don't comply with the standard.
Simple enough so far, but are there any pitfalls? Yes, but they tend to be a bit subtle.
Show your Intentions
Since Fortran 2003 an array argument to a function can have the "ALLOCATABLE" property, and that means that you can allocate and deallocate the array inside the function, for example
SUBROUTINE alloc_fn(els, array)
INTEGER, INTENT(IN) :: els
INTEGER, DIMENSION(:), ALLOCATABLE, INTENT(INOUT) :: array
IF (ALLOCATED(array)) THEN
PRINT *, "Deallocating"
DEALLOCATE(array)
END IF
ALLOCATE(array(els))
END SUBROUTINE alloc_fn
Nothing terribly surprising there. I call my function the first time on an unallocated array and it silently allocates, and if I call it again then it prints "Deallocating" and reallocates the array to the new size.
But what if I switch the INTENT argument of the array from "INOUT" (meaning that I can both read and write data to the array) to "IN" (meaning that I can read data from the array but not make changes). Happily as you might expect the compiler refuses to compile this code because it involves making changes to the array and I've specified that I can only read data from it.
But what about if I switch the intent to "OUT" (meaning that I can put data in the array but not read data from it)? You would probably expect this to work because I'm not using data from the array, but on second thoughts you might expect it to fail because I am testing the allocation status of the array. Well, if you try it it compiles, it runs and it allocates the array as expected. The strange thing is that the "Deallocating" print statement never triggers, and this is exactly how Fortran reads the "INTENT(OUT)" statement for allocatable arrays. Since INTENT(OUT) is supposed to mean that you don't take any information from this variable you must be assuming that it is not allocated when it enters the function SO IT DEALLOCATES IT IF IT IS ALLOCATED! This is useful but you have to be very careful! The same behaviour happens for types that contain allocatable components so watch out!
Coming Next - Pitfalls of Allocatables
There are more things to watch out for with Fortran allocatables, including the behaviour of array bounds when they are passed into functions in different ways, automatic reallocation of variables during array assignment (that sounds good but can cause absolute chaos!), the behaviour of types containing allocatable components and a few similar bits, but those will have to wait for part 2 of this post.
Heather Ratcliffe
07 Aug 2019 13:23
| ![]() Tags: Fortran Memorymanagement Programming
| Comments (0)
|
Tags: Fortran Memorymanagement Programming
| Comments (0)
| 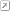 Trackbacks (1)
| Report a problem
Trackbacks (1)
| Report a problem
July 24, 2019
SOUP: The FizzBuzz Variations
I like challenges - sometimes I do maths and programming puzzles for fun. It's good practice, and if you go into industry as a programmer you may well get hit with this sort of thing in an interview. Interviewers want to verify that somebody can vaguely code before moving on to more detailled questions, so often set something simple, but originally, novel. The novelty has rather been eroded now, so you can find entire sites dedicated to compiling these questions and drilling them - which we definitely don't recommend here - but they are a good source of challenges.
One classic "challenge" is FizzBuzz. You may have encountered this as a game - I remember it from Secondary School French lessons, to help learn the names of numbers. The basic idea is very simple - you go through reading out the numbers, usually from 1 to 100, and for every multiple of three, substitute the word "fizz", for every multiple of five, the word "buzz" and for multiples of three and five (i.e. fifteen) "fizzbuzz".
For anybody who has done maths past GCSE or so, you've probably met Modulo division in some form. But the best thing about FizzBuzz is that you don't need to have. In fact, there is a complete solution without using anything except addition and equality-checking. Moreover, the core problem is nice and simple, so anybody should be able to create the pseudo-code version even if they have no idea how to check for being a multiple of three or five.
I once read an article from somebody who thought that FizzBuzz was a terribly difficult problem that needed high-level maths to solve. In the comments was somebody claiming that anybody who could just write out the code must have spent far too long drilling interview questions. That seemed a little absurd, but it did make me want to produce a FizzBuzz solution which did indicate spending far too much time thinking about it. Just to see if it was possible.
More seriously though, simple problems like this can be made into a great little challenge. There are many solutions, and you can make the problem almost arbitrarily hard by imposing artificial restrictions. You can always verify the answer, and you can get surprisingly creative. I've compiled a bunch of variations on FizzBuzz, from the outline, to the "cleverest" solution I could create, to illustrate the learning opportunity of this sort of thing. They are all on Github here.
FizzBuzz outline code
Anybody who can program should be able to turn the description above into psuedo-code, which is itself a handy skill. Here, all you have to do is expand the words into something slightly more precise. For example:
loop variable i from 1 to 100 if i divides by 3, but not 5, print "fizz" else if i divides by 5, but not 3, print "buzz" else if i divides by 3 and 5, print "fizzbuzz" else print i end loop
So, here is the first place where knowing some maths will help us: I wrote those three branches very carefully to be independent. But they don't need to be! I could just do this:
if i divides by 3: print "fizz" set flag indicating not to print i if i divides by 5: print "buzz" set flag indicating not to print i if not flag: print i
Note that this is not necessarily better! It's different, sure, but to get this to work I need to add an extra flag variable, and have three independent "if"s rather than one "if-else" chain. We can work around this pretty easily, by constructing a string rather than printing it directly, such as (I have this in the repo in Fortran as StringConstructionFizzBuzz.f90)
string = "" if i divides by 3: string = "fizz" if i divides by 5: string += "buzz" if string =="": string = str(i)
Before going on to real code, note the other possible approach, if we didn't have a handy way of checking for divisibility:
loop variable i from 1 to 100
increment counter_3s
increment counter_5s
if counter_3s equals 3
print "fizz"
set flag_not_print_i
counter_3s = 1
if counter_5s equals 5
print "buzz"
set flag_not_print_i
counter_5s = 1
if not flag_not_print_i
print i
Both of these "stock solutions" are in the repo in C, Fortran and Python as FizzBuzzModulo and FizzBuzzCounter.
FizzBuzz as a challenge part 1 - pseudo codes
So, what might we come up with as a deliberate variation on this? Well first off, lets fall back onto the "You Aren't Going to Need It" and assume that 3, 5, and 100 are absolutely fixed. Then we have a super simple solution:
print 1 print 2 print "fizz" print 4 print "buzz" ...
Simple, and it works. But it's seriously inflexible and we have to type a lot!
But wait a moment! There's a pattern here, isn't there, and it repeats every 15 lines. So what about
i = 1 while i is less than 100 print i increment i print i increment i print "fizz" increment i print i increment i print "buzz" ... print i increment i print "fizzbuzz" increment i end while
Where the ellipsis (...) is, we have enough lines that i ends up as 15 on iteration 1. The nice thing about this, is that we've relaxed the requirement that the end be at exactly 100. Except we have a rather large bug here: we get a multiple of 15 lines, every time. We'd need to find another way of stopping on the last round. In the GitHub repo for this post, I have a silly example using Bash taking this approach (UnrolledFizzBuzzGenerator.sh). It is undoubtedly silly, but this sort of approach is a pretty long way from the obvious first idea, which was after all the intention.
Note the biggest downsides of this code: it is not obvious what it's doing because it is unpacked a little too much, and the 3 and 5 are baked right into the code.
Fizz Buzz Without If
That last example was my first attempt at writing FizzBuzz without using "if", which technically it did achieve. However, "while" can trivially be used to replace if (assuming a language or variant that runs 0 times if the condition is untrue). We can do better than that, surely?
Of course we can, but first we need to think hard about what "if" is doing for us here.
Understanding What If Does
First, we need to find a way of describing the action of "if" without using the word "if". (Note that modern processors actually have inbuilt instructions called "jump-if" so this isn't strictly true, but helps us find a way to code the problem without using "if"). Note that "on" counts as a synonym here.
Consider a simple one line if chain such as
1 if (condition) 2 do thing one 3 else 4 do thing two 5 end if
If the condition is true, we end up on line 2, otherwise we end up on line 4. Then, we end up on line 5 and carry on. So, putting on our geeky hats and trying to be clever, we might think "aha! We end up on line (2 + 0 (true)|2 (false)).
The next step is far more intuitive if you come from C, or one of the other languages where true is just a number. In C, we can write something like
index = 2 + 2 * (condition != true) and get 2 if the condition is true, and 4 if its not, because "true" has value of 1, and false has 0.
Using an actual "goto" instruction is, of course, evil (not entirely true, but good enough), and in this case would be the essence of solving the letter of the problem, rather than the spirit. We need to think more generally.
Function Pointers
I have written before about using function pointers to replace "if" conditions. In this case we can't set a pointer beforehand, but we have just worked out how to replicate the if chains in our original pseudocode. So, what if we made an array, and used something like the expression above to calculate the offset into it, and then called the function we find there?
This variant works pretty well in C, but in Fortran, where Logicals are a distinct kind of variable, it is very clumsy to calculate the offsets, but can be done. This example is in the repo as FunctionPointerFizzBuzz.f90, .c and .py.
Once again, this a fairly silly way to solve FizzBuzz itself, but does use a technique that can be very very handy! Practice with this sort of thing on a silly example is a great way to learn, and if you keep these sorts of snippets around, you have something to refer to when you need to use the technique in anger later.
FizzBuzz for C programmers
The last example, which is the cleverest I could manage to be about this, is pretty deeply based on C semantics. It relies on both how C handles it's strings, and how its pointers work. I'm not going to explain what is going on, but I thought of it after trying to simplify the function pointers example because of how similar the print commands were. This example is in the repo as SillyStringFizzBuzz.c
This example really goes overboard on the cleverness and is not an approach I would ever use in "real code", but it was fun to write and a good challenge. I think it meets my original challenge pretty well - it is FizzBuzz being entirely too clever. If this sort of things appeals, look up the idea of Code Golf and/or Obfuscated C - coding answers to puzzles which are very very short and hard to understand.
That might sound exceptionally silly - why would anybody want to program in a way that's hard to understand? But of course, knowing what's hard to understand really helps know what makes things easy, and brings to your attention all of the sneaky things that might not do what you first think.
Wrap Up
To conclude - there can be a lot to learn even from super simple seeming challenges. In particular, you can lay the challenge of not using some code feature, especially one you first turn to to solve the problem normally. Developing the flair for thinking "outside the box" is very handy when you have such challenges imposed externally.
Cleverness that makes you say "oh that's clever" is often not a good thing - your first reaction should probably include "oh OK, I see how it works" before "that's clever". But developing clever solutions is a good way to learn. Think of it like something like keepy-uppies for a football (soccer) player. They're not a skill that's useful in a game (the Wikipedia anecdote about Scotland not-withstanding) but they develop control skills that absolutely are. It's also a handy display piece to demonstrate those skills, should you need one.
Heather Ratcliffe
24 Jul 2019 13:44
| ![]() Tags: Programming Soup
| Comments (0)
| Report a problem
Tags: Programming Soup
| Comments (0)
| Report a problem
July 10, 2019
Datastructures – Linked lists part 3
Follow-up to Datastructures – Linked lists part 2 from Research Software Engineering at Warwick
This time we're presenting the final piece of the puzzle for linked lists - adding items. Adding items is very, very similar to removing them. To add an item "I" between two other items (lets call them "A" and "B", with A <-> B initially) you just have to set it up so that A's next pointer points to I, B's prev pointer also points to I and that I's prev pointer goes to A and I's next pointer goes to B. You do then have to take care if either A or B don't exist (i.e. you're adding at the start or the end of the list) but basically the idea is always the same. When you don't have a standard that you have to follow interface design in programming is often as much an art as a science and there are several ways of implementing a useful interface to do this. You can write a routine "insert_between(I,A,B)" that adds an item between two specified items (although this the has to deal with what should happen if you try to insert between two items that are not actually linked to each other and also requires the developer to provide redundant information. If this is going to work then A must be linked to B so if you know A you know B and vice versa). To add at the start of the list you specify "A" to be NULL, and to add at the end of the list you can specify "B" to be NULL. This isn't seen very often in the wild but it works perfectly well. You could also write "insert_after(I,A)" and "insert_before(I,B)" routines that would allow you to insert item I either "after A" or "before B", again specifying appropriate NULL items for A or B to add to the start or the end of the list. The most common approach in the wild at the moment is that used by the C++ Standard Type Library containers. Have a routine "insert(I,B)" that inserts the item before a specified item B, a routine "insert_after(I,A) to insert an item after the specified item, a routine "push_back(I)" that adds a new element to the end of your list and a "push_front(I)" routine to add the new item at the start of the list. While I'm not sure that I'd pick them from scratch I'll stick to the STL
void insert(llitem* head, llitem* new, llitem *before)
{
new->next = before;
if (before->prev) {
before->prev->next = new;
new->prev = before->prev;
} else {
head = new;
}
before->prev = new;
}
void insert_after(llitem* new, llitem *after)
{
/*head is not used here because inserting after an item cannot touch the head*/
new->prev = after;
if (after->next) {
after->next->prev = new;
new->next = after->prev;
}
after->next = new;
}
void push_front(llitem* head, llitem* new)
{
if (head){
head->prev = new;
}
head = new;
}
void push_back(llitem* head, llitem* new)
{
llitem * current = head;
if (!current) {
head = new;
} else {
/*spin on until you find an item that has no next element. That element is the end of the list*/
while(current->next) current = current->next;
current->next = new;
new->prev = current;
}
}
SUBROUTINE insert(head, new, before)
TYPE(llitem), POINTER, INTENT(INOUT) :: head !Head of linked list
TYPE(llitem), POINTER, INTENT(INOUT) :: new !Item to be inserted
TYPE(llitem), POINTER, INTENT(INOUT) :: before !Item to insert before
new%next => before
IF (ASSOCIATED(before%prev)) THEN
before%prev%next => new
new%prev => before%prev
ELSE
head => new
END IF
before%prev => new
END SUBROUTINE insert
SUBROUTINE insert_after(new, after)
!No head pointer because inserting after an item can't touch the head
TYPE(llitem), POINTER, INTENT(INOUT) :: new !Item to be inserted
TYPE(llitem), POINTER, INTENT(INOUT) :: after !Item to insert after
new%prev => after
IF (ASSOCIATED(after%next)) THEN
after%next%prev => new
new%next => after%next
END IF
after%next => new
END SUBROUTINE insert_after
SUBROUTINE push_front(head, new)
!No head pointer because inserting after an item can't touch the head
TYPE(llitem), POINTER, INTENT(INOUT) :: head !Head of the linked list
TYPE(llitem), POINTER, INTENT(INOUT) :: new !Item to be added to the list
IF (ASSOCIATED(head)) THEN
head%prev => new
END IF
head => new
END SUBROUTINE push_front
SUBROUTINE push_front(head, new)
!No head pointer because inserting after an item can't touch the head
TYPE(llitem), POINTER, INTENT(INOUT) :: head !Head of the linked list
TYPE(llitem), POINTER, INTENT(INOUT) :: new !Item to be added to the list
TYPE(llitem), POINTER :: current
current => head
IF (.NOT. ASSOCIATED(current)) THEN
head => new
ELSE
DO WHILE(ASSOCIATED(current%next))
current=>current%next
END DO
current%next=>new
new%prev => current
END IF
END SUBROUTINE push_front
Once again a diagram will probably make things clearer.

There is one thing that you can spot easily from the implementations : in order to add to the end of the list you have to cycle through all of the intermediate items to get to the end. This isn't actually a major problem since for a lot of the uses of linked lists you can freely choose to add to the start of the list which happens immediately by just updating the head. However if you want to be able to add to the end of a linked list then it is common to actually store an equivalent of the "head" item that marks where the end of the list is. This item is generally called the "tail" item. I haven't described anything about using tails because it doesn't add anything to the fundamental nature of the linked list while making all of the implementation a little bit messier. Holding the tail also introduces a debugging risk because it is (technically) redundant and can be inconsistent with the actual last element that you would reach by iterating through the list (usually only because of errors in your implementation). The addition of multiple sources of information about something always complicates matters and you have to test very carefully to ensure that they can't become inconsistent.
This series has basically described how to implement a very simple linked list (if you wanted to). There are many limitations and weaknesses of this implementation (not being certain to nullify pointers on items when adding them, not having a tail item and also the fact that each item can only be in a single linked list at any point (usually you relax that requirement by having each llitem have a pointer to your real data rather than holding the data within the llitem structure itself. You do have to be careful to make sure that items are fully deleted when the last reference to them is released though!)) but it does, mostly, work. The final part of this series on linked lists is going to go through why you might not want to use them. Not just this limited implementation but when linked lists are not suitable datastructures and how you can create hybrids of linked lists and arrays that can perform much better.
Christopher Brady
10 Jul 2019 14:46
| ![]() Tags: Code Programming Training
| Comments (0)
| Report a problem
Tags: Code Programming Training
| Comments (0)
| Report a problem
June 27, 2019
"And then it just clicked
A bit more of the general "philosophy of programming" today, based on a quote I found on the brilliant "C FAQ", currently here and hopefully there to stay. The quote is from Q 18.9b, on learning resources and says:
A word of warning: there is some excellent code out there to learn from, but there is plenty of truly bletcherous code, too. If you find yourself perusing some code which is scintillatingly clear and which accomplishes its task as easily as it ought to (if not more so), do learn everything you can from that code. But if you come across some code that is unmanageably confusing, that seems to be operating with ten bandaged thumbs and boxing gloves on, please do not imagine that that's the way it has to be; if nothing else, walk away from such code having learned only that you're not going to commit any such atrocities yourself.
It's a very good idea to read other people's code when learning - either completely in the wild, or in the form of snippets on sites like Stack Overflow. But always keep in mind that there is some truly terrible code out there, even in commercial packages. It's easy to fall into the trap of thinking that your problem is just "soooo hard" that it just can't be done elegantly, or readably, or even conforming to standards, at all, and mostly that just isn't the case.
Obviously, different people will find different things to be readable, clear, elegant etc. I have an Undergrad degree including Maths, and I rather like the shorthand notation of sums and sets and implication. To some people though, the symbols are simply "all Greek" (pun thoroughly intended). Writing things in a way everybody will find clear is thus often a losing battle. But there is one very very important thing to avoid at all possible costs : the anti-click.
The Click
The 'click' is that feeling of clarity when you jump from grasping the parts of the thing to understanding the whole. I get it a lot with things like Anagram word puzzles, or even song intro quizzes (the kind where you're meant to guess the title). One moment you're seeing a jumble of letters, trying to hold all dozen in your head, and the next you can 'see' the word it must be. Similarly, one moment you're following along the notes and words and the next the key lyric pops into your head and the song is obvious. Optical illusions do it too - and once you've seen it you struggle to "un-see" it again.
This is the 'click' and it's a real asset that you can develop with practice, by reading plenty of code, and writing plenty of code, until you can 'get the gist' of the thing easily.
Symptoms and Diagnosis
It also comes up a lot in debugging - you just 'get the hang' of the way an error pops up, and know what must have happened. That's why reading issue trackers or mailing lists can feel so confusing - the people answering the questions seem to have some mysterious knack for guessing what's wrong from the most un-intuitive errors.
For example, writing in C you may use a function like 'sqrt', and get a 'undefined symbol' error from the linker, which is saying that it can't work out what that function is. So, being logical, you go back and check that you have absolutely definitely included the "math.h" header, which absolutely definitely contains a sqrt function. What did you do wrong? Well probably you forgot to compile using the '-lm' flag, which means "link against the maths library", because that library contains a lot of compiled code (the code isn't in the math.h file). This error can seem very weird, but actually, once you know the cause, it's "obvious".
We had a go at writing a catalogue of programming bugs a while ago, which tried to sort of encapsulate the 'symptoms' of a bug (available here, PDF download). Any bugs, errors or omissions please let us know (rse {@} warwick.ac.uk). Once you see enough bugs, you'll probably start to 'click' and 'just know' what to look for.
The Anti-Click
I mentioned optical illusions up there, and how you can't seem to "unsee" them. Sometimes code has this same sort of thing - an illusory apparent action or cause which is actually not real. This can be awkward and dangerous, because you, and others, will struggle to "unsee" it. It's hard to give an example that isn't really contrived, so I shall fall back onto a classic bit of C: pointer declarations.
In C, you declare pointers using a '*', such as `int * p;`. This is fine. But what about `int * p, q;`? Is q a pointer? No, it's not. Some people argue that the "proper style" will prevent this anti-click, that is, writing that as `int *p, q` and associating closely the * and the p. This is surprisingly hotly debated (e.g. hereand here) with some really tempting anti-clicks (such as here- do read the answers, as the OP there is wrong) but ultimately does need careful thought. You're probably best using whatever you personally find clearest, and changing that only after consideration.
The golden rule - DO NOT write misleading code, docs etc etc. Make it wordy if you have to, but it's not worth the hassle of an obvious, yet wrong, interpretation. As a last resort, just put in a comment explaining what this does not mean, or does not do.
And the flip side - NEVER trust the click - always verify. Always step through line by line and be sure you're right!
Click Immunity
One last thing - there are people for whom some things just never do 'click'. It's very hard to describe, but easy to spot. It's sort of like trying to explain computers to that one relative or quadratic equations to somebody who can't do maths. They're clearly not stupid, but they just don't seem to 'get it'. You explain one thing, like how to print, and it works, but now they need to print from a different program and isn't it just obvious that you do the same thing?
Some people seem to have a knack even beyond that - they don't just "not get it", it's worse! Bug reports display this sometimes - somebody who always gives a lot of information but somehow never includes the vital pieces. They'll post a 100MB log file, but forget to mention which OS. They'll explain exactly what commands they ran but omit some vital parameter.
There's two sides to this - dealing with people who don't click, and dealing when you can't click.
Hell is Other People
Usually you only have one real option to deal with other people who don't get it - guide them through it. Mostly, it just takes longer, not happens never. You probably want to try explaining things different ways, because what feels neat and obvious to you isn't to them. The Socratic style is handy - ask them what they're trying to do, or what they feel they should do, rather than telling.
I just don't GET IT
I expect everybody, sooner or later, finds something that just doesn't click right. You don't get it - it's unintuitive, your gut feeling is always wrong etc. So what do you do? Treat yourself the same as you would somebody else - read different explanations until you find one that fits you. Ask yourself "what am I trying to achieve". Ask yourself "when I ask this question, what might somebody need to answer it" - and if in doubt, ask them! Stop assuming anything, and walk through every step of the problem.
Walk away and do something else - give your brain time to work things through. Never stop asking questions and always learn from the answers. You don't need to 'click' to do something, you just need to watch for wrong intuition. Keep notes - add comments in your code for you to come back to.
Remember - intution is a skill like any other. It can be wrong. And while you might not have a talent for this thing, but with effort, you can make it work.
Heather Ratcliffe
27 Jun 2019 12:56
| ![]() Tags: Philosophy Programming
| Comments (0)
| Report a problem
Tags: Philosophy Programming
| Comments (0)
| Report a problem
June 12, 2019
Datastructures – Linked lists part 2
Follow-up to Datastructures – Linked lists part 1 from Research Software Engineering at Warwick
This entry is back to the subject of linked lists. In the previous post on linked lists we described the idea of a linked list and how you created one. In this post I'm going to talk about how you remove items. The idea is pretty simple, to remove item "n" you want item "n-1" to believe that the item after it is now item "n+1" and you want item "n+1" to believe that the item before it is item "n-1". There are a few wrinkles to deal with if the item is at the start of the list (recall that this is usually called the `head` element) but mostly the idea is this simple. This is most easily shown by a code example recalling the definition of linked list items from part 1.
void remove_item(llitem *item, llitem *head)
{
if (item->prev) {
/*Item has an item before it in the list*/
item->prev->next = item->next;
} else {
/*Item does not have an item before it. It is the head*/
head = item->next;
item->next->prev = NULL;
}
if(item->next) {
item->next->prev = item->prev;
}
free(item);
}
SUBROUTINE remove_item(item, head)
TYPE(llitem), POINTER, INTENT(INOUT) :: item !Item to be removed
TYPE(llitem), POINTER, INTENT(INOUT) :: head !Head of linked list
IF (ASSOCIATED(item%prev)) THEN
!Item has an item before it in the list
item%prev%next => item%next
ELSE
!Item does not have an item before it. It is the head
head => item%next
item%next%prev => NULL()
END IF
IF (ASSOCIATED(item%next)) THEN
item%next%prev => item%prev
END IF
DEALLOCATE(item)
END SUBROUTINE remove_item
This routine removes an item from a linked list and deals with changing the head of the list to match if needed. After the item is removed from the list it is deallocated. You might not want to do this automatically when an item is removed from a list (you can have multiple lists and freely move items between them) but you do have to do it when you are finished with the item or you will have a memory leak. One of the downsides of linked lists is that since they involve direct pointer operations in normal use memory leaks are a greater risk than in many data structures.
You can also see what's going on in a diagram showing how you remove both a "normal" and a "head" item from the linked list. In both cases links shown in green are new links and links shown in orange are links that are being deleted or changed.
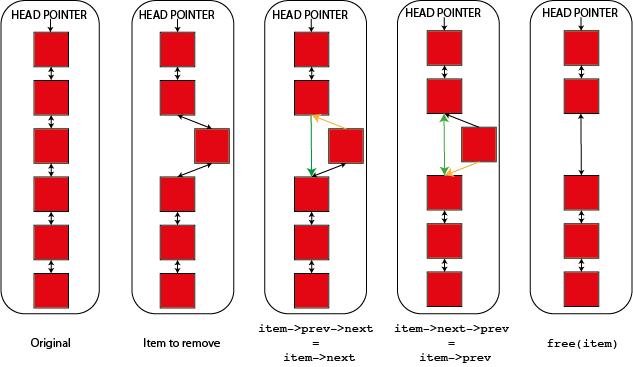
Hopefully the idea is quite clear between the code and the diagrams. If "item" is item "n" in the list then "n-1" is item->prev and "n+1" is item->next. Either or both of these items may not exist if "item" is either the start or the end of the list so you have to cope with these cases. So to update the next element of "n-1" you have to set "item->prev->next" which looks a bit odd but makes sense if you unpack it. Similarly the "prev" element of "n+1" is "item->next->prev".
You will notice that the links on the item being removed aren't touched and the code simply relies on that item being deleted immediately. In a system where you want to retain an item (perhaps to add it to another linked list) you'll probably want to nullify it's prev and next pointers after you remove it from the list.
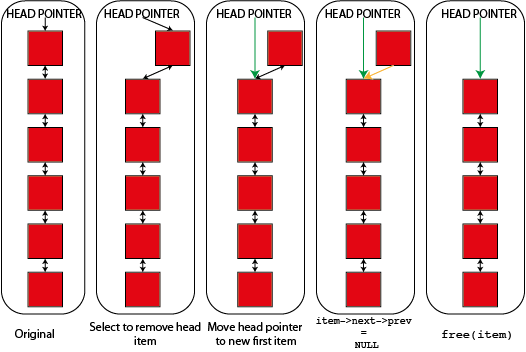
That code will remove any item from the linked list that it is in. There is however a problem if you have multiple lists, each with it's own head element. Imagine that I tried to use that "remove_item" function where I passed it an element from one list but the head from a different list. So long as "item" isn't the first item of the list that it is in then nothing would go wrong but as soon as it is it would replace the head of the second list. This would cause real problems
- The list that "item" was in will become invalid. Because it's "head" element is never updated it will still point to the now deleted "item" and will sooner or later fail when you try to use it. It might, for a while, look as though "item" hasn't been deleted because of this
- The original list that you specified the "head" from will now be lost completely. The only reference that you have to a linked list is the head element so if anything happens to this the memory is lost forever. You have both lost data and caused a memory leak
- You have also moved data. The list that you specified the head from will now be a valid list, but it will be the list that "item" was originally part of, not the list that is meant to be there.
This type of error in a linked list thus causes memory leaks, segmentation faults and data corruption all in one nice package so you have to be careful to avoid it. You can program in safeguards to prevent doing things like this but they do slow down the operation of the linked list and require extra memory (as well as making rather harder some nice tricks that you can do with linked lists that I'm not going to talk about here) so many working linked list implementations don't bother. You can see graphically what's happening here too.
Mostly linked lists in operation are stable and reliable but it is possible to get yourself into a bit of a tangle. But you can immediately see that this makes is a lot easier to remove an element from the middle of the linked list than if you had an array. If you had an array then you'd either have to flag that item as "invalid" somehow to know that you shouldn't use it anymore or failing that actually copy all of the elements in your array above the item being removed down to fill the gap. The first one adds complexity and means that you can't actually reduce your memory footprint when removing items (not quite true if you use an array of pointers to items but that's even more complicated) while the second is quite often very slow. This is especially true if you use a library that guarantees contiguity of the elements of your array after every delete operation when you are deleting multiple items (e.g. std::vector in C++. This behaviour is generally an advantage but here is a cost. You can get around it in other ways in C++ but other libraries are less flexible). The cost is managable if you delete many items and then pack the array up but packing after every deletion can be very costly.
The next entry in this section will describe adding items to a linked list which, as you might imagine, is quite similar to deletion but in reverse.
Christopher Brady
12 Jun 2019 16:31
| ![]() Tags: Code Programming Training
| Comments (0)
| Trackbacks (1)
| Report a problem
Tags: Code Programming Training
| Comments (0)
| Trackbacks (1)
| Report a problem
May 30, 2019
Black and white
Quick 'philosophy of programming' entry this time. General solutions to common programming probelms are often called 'design patterns' (e.g. the wiki articleor the book which started the name). The idea of these is to have language independent (as far as possible) 'patterns', like clothing patterns, which can be tweaked to fit a specific situation. A lot of these patterns seem obvious, which is good, and since they're developed and tested by many people they can be very valuable in showing you questions you hadn't even thought of.
This weeks topic is perhaps too simple to really call a pattern, but it is a very useful thing to keep in mind when doing anything that deals with restricting function which exists, but should not be allowed. For example, forms which take user information often disallow anything except numbers in a 'telephone' field. A code I work on has a lot of user-specifiable options, but as the programmer I know that some are incompatible where it might not be obvious to the user - and I want to either warn or abort if these are used together.
There are two general approaches to things like this, and which you choose depends on many things. You have to maintain some kind of list to check against, but you can choose to use either the "blacklist" or the "whitelist". The former, the "blacklist" is a list of the things which aren't allowed, and anything not in the list is OK. The "whitelist" approach means keeping a list of the things which are allowed, and anything not in the list is excluded.
Sometimes the choice is fairly easy, because one method is a much, much simpler list. For instance, in the phone number example, it is fair easier to use the whitelist, allowing only '1234567890', but nothing else. If you try the other way, you might think to exclude letters, but what about Greek or Cyrillic characters? On the other hand, this is a source of deep annoyance if you forget any needed character - in the example I just gave, one could not put any spaces in, which is annoying, nor brackets or the '+' symbol.
A classic example of the poorly-thought out whitelist is in name fields which often exclude characters like the apostrophe, annoying the Scots and the Dutch for eternity. And what about accented letters, or the German ess-tsett. With a whitelist, you need to be sure you've caught everything, or people will be, rightly, upset. For a user-name on a website, and for a password, it is probably fine to allow any ASCII or Unicode character and set up your systems to handle them, leaving far less upset without any real cost to you.
On the other hand, with a blacklist, anything not forbidden is permitted. These are generally used in cases where certain characters have a function and so must be excluded, even if this annoys. So, for instance, in most programming languages variable names may not start with a number, nor contain a comment character.
Apart from the length of the lists, the two methods trade off this annoyance to your user, who must wait until you fix the omission (with a whitelist) against potential unknown failures and security risk (with a blacklist). Imagine the 'incompatible features' problem with both methods. If I use a whitelist, and forget to allow some pairing, my worst case is that I will likely be asked (somewhat irately) why X and Y can't be used together. I realise they can be, I update the code and I make a new release version to fix the omission and everybody is happy. If I use a blacklist and forget that some X and Y don't work together, my worst case is that one day I have to tell somebody that their last n years of research is all invalid, because the simulation they ran didn't work as expected, and since nothing actually went wrong they didn't know. Worse still, would be having to tell them that their fascinating effect is just a code error, and it's my fault.
In some cases, only one or other list type is really viable. For instance, virus scanners keep a list of 'tells' for malicious code, because even though they let things slip through until their lists update, they could never describe all of the 'allowed' code. App permissions (on better, more granular systems) are a whitelist - you give an app the permissions you choose, and only those.
So as a general rules of thumb:
- If only one method is viable, obviously use that
- If one or other list is going to be much much shorter, you have better chances of getting it right, so use that method
- If it is really important not to let things slip through, use a carefully managed, kept up to date, whitelist. If possible, put it into a file or something, so that updates just require sending out new definitions, not modifying the entire code
- If it's really important not to get accidental exclusions (false positives) use a, similarly carefully managed, kept up to date etc, blacklist
- In some cases, combine the two. Programming languages generally have a set of allowed characters (a whitelist) and small blacklists for specific contexts such as the first character of a name.
As well as the literal 'blacklist' and 'whitelist' there is a more general principle here - do I selectively forbid, or selectively allow? Do I stop somebody doing this thing here, here and perhaps here, or do I only permit them to do it there and there. If you find the 'here's' or 'there's' proliferating, re-examine whether you're doing it the right way around. In safety or security critical situations, you almost always must allow only what is permitted. If you find yourself trying to plug up security holes with ever growing blacklists, you should probably change tack and think about what should be allowed instead.
Heather Ratcliffe
30 May 2019 15:59
| ![]() Tags: Bugs Patterns Philosophy Programming
| Comments (0)
| Report a problem
Tags: Bugs Patterns Philosophy Programming
| Comments (0)
| Report a problem
May 15, 2019
Datastructures – Linked lists part 1
Back to data structures this month with the linked list. Linked lists are a way of holding data that allows you to add and remove items quickly and easily.
Why not arrays?
First question: why is adding and removing items from an array not quick and/or easy? The problem with adding items is quite simple - arrays have a fixed size so eventually you will run out of spaces in your array to store items. When this happens you have to do something to allocate additional space. Many languages have a function called "realloc" or similar that tries to extend the length of your array but it can only do that if there is unused memory space "above" the location of your array because the array elements have to be arranged one after the other in memory. The concept of "space above" is a bit complex in general and depends on details of your OS etc. but as a general idea if you allocate two arrays then they are placed one after the other in the computer's underlying memory so if you try to realloc the first array then there won't be any space between it and the second array to grow it in. If you can't grow your array like this then you have to allocate new memory to store the bigger array and copy the existing elements in. If you keep adding items then this continual growing of your array can be quite expensive, although this can be mitigated by always growing your array by more elements than you immediately need.
Removing items has the opposite problem. Since arrays are required to be contiguous (can't have gaps in them) you can't just "remove" an item you have to either flag it as empty and ignore it when going through your array in future or take all of the items above the removed element and move them down to pack everything up. The first approach has three problems
- You have to use additional memory to flag items as being empty or not
- If you are both adding and removing items from your array then since you don't actually recover memory when you remove an item your total memory requirements will grow without bounds
- Depending on your algorithm you might have more difficulty getting optimal performance if you have to do fundamentally different things for empty and non-empty array elements
The second approach avoids those problems but on average involves copying half of the elements in your array every time you remove an item which can also be quite expensive.
It is quite possible to build a container based on arrays that you can add and remove items from that has good general performance (C++ std::vector is a good example of one) but they always have to make tradeoffs and if you are doing a lot of adding and removing of arbitrary elements it might be better to use a data structure other than an array.
Linked lists
The idea of a linked list is quite simple. Each element in a linked list is like a link in a chain - linked to the item after them, so you go through the linked list by taking the first item then going to the next item and the next etc. until you reach the end. This is generally implemented using pointers in what are often called "self referential structures", that is structures that contain pointers to themselves. These are easy enough to implement in either C/C++ or Fortran.
struct llitem{
struct llitem *prev, *next;
};
TYPE :: llitem
TYPE(llitem), POINTER :: next, prev
END TYPE llitem
These are more or less normal types but there is one more important rule: self referential structures can contain only pointers to their own type, not actual instances of their own type (try removing the *s in C or the POINTER attribute in Fortran and it will fail to compile). This is because types, much like arrays, are laid out contiguously in memory so they can only contain things that the compiler knows the length of and if you have a type that contains an instance of itself then there would be an infinite regression problem because you don't know how big it is until you have finished creating it and you can't create it until you know how big it is. Pointers are all of a fixed size so they work OK.
The structure as given is for what is technically called a doubly linked list because it contains links both to the next item and the previous item in the list. A singly linked list has each item linked only to the next item in the list. Doubly linked lists have some substantial advantages over singly linked lists, notably that you can go through it from either end, but also you can remove an item from the list needing only the item itself (and the list that it is held in if you have several).
Creating linked lists
Creating a linked list is quite easy. You hold a simple pointer to the first element in the list (generally called the head item) and then you simply create the list going down from that. The key thing is that you have to hook up the prev and next links as you go. This isn't too difficult and looks like
#include#include struct llitem{ int value; struct llitem *next; struct llitem *prev; }; void init_ll(struct llitem * l) { l-> value = -1; l->next = NULL; l->prev = NULL; } int main(int argc, char** argv) { struct llitem *head, *current; int i; head = malloc(sizeof(struct llitem)); init_ll(head); head->value = 1; current = head; for (i=0;i<10;++i){ current->next = malloc(sizeof(struct llitem)); /*Create the next element*/ init_ll(current->next); /*Initialise it to nullify pointers*/ current->next->value = current->value + 1; /*Simple counter*/ current->next->prev = current; /*It's previous pointer should be the current item*/ current = current->next; /*Now move onwards so the newly created particle is now current*/ } current = head; while(current){ printf("%i\n", current->value); current = current->next; } }
PROGRAM test
IMPLICIT NONE
TYPE :: llitem
INTEGER :: value = -1
TYPE(llitem), POINTER :: next => NULL()
TYPE(llitem), POINTER :: prev => NULL()
END TYPE llitem
TYPE(llitem), POINTER :: head, current
INTEGER :: i
ALLOCATE(head) !Create the head
head%value = 1
current => head
DO i = 1, 10
ALLOCATE(current%next) !Create the next element
current%next%value = current%value + 1
current%next%prev => current !The next element's previous is the current element
current => current%next !Now move onwards so the newly created particle is now current
END DO
current => head
DO WHILE (ASSOCIATED(current))
PRINT *,current%value
current => current%next
END DO
END PROGRAM test
This example also shows how you how to step through the linked list from the head, simply by having a "current" pointer that starts at head and is then incremented by setting current = current->next (or current => current%next in Fortran). This can look a bit odd but it isn't that hard to understand. I start by manually creating the "head" element, using either ALLOCATE or malloc. Once I have a head element I then loop through, each time using the same ALLOCATE or malloc command on the "current->next" pointer, creating a new item every time. In C I then call the ll_init function to setup the values of the struct (in Fortran this is done for me since I gave the elements of my TYPE default values). After this the prev and next pointers are both NULL. This is correct for the next pointer becuase my new item is the last item in the list (it won't be next iteration but right now it is), but I have to set the prev pointer. If my new item is the next element in the chain from my current element then the previous element in the chain from my new element must be my current element so I set that up. After that I just have to repeat until I have added enough items.
Part 2 of this will be in a couple of weeks and will describe how you remove and item from a linked list and how to add new items to the middle of a linked list.
Christopher Brady
15 May 2019 17:20
| ![]() Tags: Code Programming
| Comments (0)
| Trackbacks (1)
| Report a problem
Tags: Code Programming
| Comments (0)
| Trackbacks (1)
| Report a problem
May 01, 2019
The Numba "stencil" directive
After a bit of a delay we're getting the blog posts going again with a mention of a slightly odd bit of the Python Numba compiler - the stencil directive. The purpose of Numba is to produce compiled code from Python source that should run at a reasonable fraction of the speed of classical C/Fortran etc. codes. In general it produces codes that is about 20-40% as fast as C or Fortran code, so typically only about 1-2% as fast as the computer can theoretically operate. In general, the more that you can tell Numba in advance about how you are going to use your data the more options it has to optimise the code as it compiles it. The "stencil" directive is used to indicate to Numba that you are going to operate on an array by moving a stencil across it and updating each point using data from neighbouring points.
This is a fairly common thing to want to do and crops up in algorithms from image smoothing to numerical solutions to differential equations so this is a useful bit of the library. As a simple example consider the simplest possible image smoothing algorithm. For each pixel in the image P(i,j) replace the value with the average of the surrounding pixels, so
P'(i,j) = 1/4 * (P(i+1,j) + P(i-1,j) + P(i,j+1) + P(i,j-1))
Note that the left hand side of this equation is P' not P, so when we calculate the average for each pixel using the original values surrounding it not the values that have already been through the averaging process. After you have finished you copy P' to P. There is then one last thing that you have to worry about: what do you do when you reach the edge of the array? Since you are using adjacent cells you have to do something or you will read outside your array. Numba's stencil operator at present only has two options: set the outer cells to be zero or some other constant value. In general, this will mean that you want to have an outer strip of cells added around your image otherwise your image will get smaller as it smooths. These outer cells are often called ghost or guard cells and are also common in numerical solution of differential equations for representing boundary conditions. The code for doing all this in Python is quite simple
def blur(A):
s = A.shape
B = np.zeros((s[0],s[1]))
for i in range(1,s[0]-1): #Range only over the inner cells
for j in range(1,s[1]-1): #Range only over the inner cells
B[i, j] = 0.25 * (A[i-1,j] + A[i+1,j] + A[i,j-1] + A[i,j+1])
return B
This code takes a numpy array and iterates over all but the outer strip of cells in every direction, averages and returns the value. Each call to this function smooths your image a bit (by a radius of about 1 pixel) so in general you'll want to call it several times to smooth your image as much as you want. Running this algorithm on a stock image of 1529 x 2250 pixels on a 3.4GHz processor takes about 3.3 seconds per iteration using the pure Python implementation and 0.006 seconds by using the Numba @njit decorator. For testing we ran 100 iterations of the pure Python code and 1000 iterations of the Numba code. If run to the same number of iterations, the results in both cases is the same


The simple equivalent using stencil is
@numba.stencil
def blur(A):
return 0.25 * (A[-1,0] + A[1,0] + A[0,-1] + A[0,1])
You can see how i-1 becomes just -1 and similarly for other parameters in the stencil, and you can also see how this operation now becomes a one-liner so it's much easier to write. Unfortunately the performance is much worse than the @njit version too taking about 0.22 seconds per iteration, although that is still some 10x faster than the native python performance. Fortunately performance can be improved by calling the stencil from a Numba jit-ed function, so for example
@stencil
def inner_blur(A):
return 0.25 * (A[-1,0] + A[1,0] + A[0,-1] + A[0,1])
@njit(parallel=False)
def blur(A):
return inner_blur(A)
The result from this method gives performance that is indistinguishable from that of the direct Numba jit version and is still rather shorter. Since these stencils lay out the data dependency you can also set parallel=True in the @njit call and this can be quite succesful but tends to work better for more complex stencils. In this particular case despite showing the Python interpreter apparently using 6 cores solidly the execution speed slows down by a factor of 3.
Christopher Brady
01 May 2019 14:04
| ![]() Tags: Programming Soup
| Comments (0)
| Report a problem
Tags: Programming Soup
| Comments (0)
| Report a problem
February 27, 2019
Data structures – Stacks
Another fairly simple data structure this week - the stack. The stack is basically the reverse queue. Rather than the first item to arrive being the first to be served as with a queue in a stack the last item to arrive is the first to be served. The name comes from the idea of a stack of paper where you add pages at the top and then take them off the top again when you want them. Formally this behaviour is called LIFO (Last In First Out) as opposed to the FIFO (First In First Out) queue.
As you might imagine this is quite a restrictive data structure and the classical stack actually only has two operations
- push - add an element to the top of the stack
- pop - take the top element off the stack and give it to you
You'll notice that pop and push are inverses since pop removes the top element from the stack and gives it back to you. This isn't always what you want since you might find that you have to simply push the element back onto the stack if you can't deal with it yet. To make this easier a lot of stack implementations also have a snoop operation which tells you what is on the top of the stack without actually taking it off. What you never have in a true stack is a way of accessing an arbitrary element in the stack. If you can do that then you have an array that you are accessing in a "stack-like" way. This is also something that people quite often want to do, so you find that lists in Python have a "pop" method to remove the rightmost element (although the equivalent of "push" is called "append" for a Python list, probably because it is used for a lot more than making stacks).
Implementations of stacks are generally very simple. The simplest implementation is just an array with an index to the first free element in the stack. When an element is pushed it is added at that location and the index is moved on by one element. When a pop happens the element behind the index is given to the user and the index is moved back by one.

This will all work perfectly well until you run out of space in your array when, much as with the queue, you have to do something else. You can reallocate your stack to give yourself more space, copying the existing elements as you go, you can implement a stack using a linked list (which we will cover in a later post) which means that you won't run out of stack until you run out of memory or you can refuse to accept the new item an return an error. If you do nothing and accept the new item you access memory that you are not supposed to be using at all which can cause all kinds of problems from crashes to possible security exploits and this is called a buffer overrun, which might be familiar with as one of the most common things that are listed as the cause of security problems in software.
At this point it is worth drawing a distinction between the stack as a data structure and all of the other things that are called stacks. There are call stacks that were mentioned in the last blog post which described how a program got to be in the place where it is and there is an associated CPU feature called a "stack register" that holds this information. There is "stack memory" which together with "heap memory" make up the most common way of dealing with memory management in compiled codes and there are plenty of other stacks that turn up all over the place. In general they get the name because they implement a stack data structure (sometimes they used to be a stack back when the name was given to them but no longer do) and otherwise are not really related. You have to be rather careful because lots of things are called stacks and that name itself doesn't alway tell you very much. Always read the documentation!
A question that might come to mind is "what would I ever do with a stack?" They do seem rather less use than a queue and in practice they are mostly fairly "low-level" data structures that most people don't encounter much, but you can easily enough think of cases where they are useful. Their most useful feature is as a "memory" of a sequence of events that can then be undone. Many "undo" systems in software use stacks behind the scenes for exactly this reason. For the same reason they are often used in "depth-first search" algorithms which were first investigated (and still used!) as ways of solving mazes. They also crop up in algorithms to parse mathematical and programming languages (a good example being the Shunting Yard Algorithm, named after train shunting yards. You can easily see the similarity between a stack as described here and a train siding because you can only get carriages off a siding in the reverse of the order you put them in on). But in general you probably won't need to implement your own stacks very often but it is worth knowing about them because they are so ubiquitous in the lower layers underpinning all of modern software development.
Christopher Brady
27 Feb 2019 18:00
| ![]() Tags: Programming Training
| Comments (0)
| Report a problem
Tags: Programming Training
| Comments (0)
| Report a problem
 Loading…
Loading…

