All 14 entries tagged Code
View all 36 entries tagged Code on Warwick Blogs | View entries tagged Code at Technorati | There are no images tagged Code on this blog
May 15, 2019
Datastructures – Linked lists part 1
Back to data structures this month with the linked list. Linked lists are a way of holding data that allows you to add and remove items quickly and easily.
Why not arrays?
First question: why is adding and removing items from an array not quick and/or easy? The problem with adding items is quite simple - arrays have a fixed size so eventually you will run out of spaces in your array to store items. When this happens you have to do something to allocate additional space. Many languages have a function called "realloc" or similar that tries to extend the length of your array but it can only do that if there is unused memory space "above" the location of your array because the array elements have to be arranged one after the other in memory. The concept of "space above" is a bit complex in general and depends on details of your OS etc. but as a general idea if you allocate two arrays then they are placed one after the other in the computer's underlying memory so if you try to realloc the first array then there won't be any space between it and the second array to grow it in. If you can't grow your array like this then you have to allocate new memory to store the bigger array and copy the existing elements in. If you keep adding items then this continual growing of your array can be quite expensive, although this can be mitigated by always growing your array by more elements than you immediately need.
Removing items has the opposite problem. Since arrays are required to be contiguous (can't have gaps in them) you can't just "remove" an item you have to either flag it as empty and ignore it when going through your array in future or take all of the items above the removed element and move them down to pack everything up. The first approach has three problems
- You have to use additional memory to flag items as being empty or not
- If you are both adding and removing items from your array then since you don't actually recover memory when you remove an item your total memory requirements will grow without bounds
- Depending on your algorithm you might have more difficulty getting optimal performance if you have to do fundamentally different things for empty and non-empty array elements
The second approach avoids those problems but on average involves copying half of the elements in your array every time you remove an item which can also be quite expensive.
It is quite possible to build a container based on arrays that you can add and remove items from that has good general performance (C++ std::vector is a good example of one) but they always have to make tradeoffs and if you are doing a lot of adding and removing of arbitrary elements it might be better to use a data structure other than an array.
Linked lists
The idea of a linked list is quite simple. Each element in a linked list is like a link in a chain - linked to the item after them, so you go through the linked list by taking the first item then going to the next item and the next etc. until you reach the end. This is generally implemented using pointers in what are often called "self referential structures", that is structures that contain pointers to themselves. These are easy enough to implement in either C/C++ or Fortran.
struct llitem{
struct llitem *prev, *next;
};
TYPE :: llitem
TYPE(llitem), POINTER :: next, prev
END TYPE llitem
These are more or less normal types but there is one more important rule: self referential structures can contain only pointers to their own type, not actual instances of their own type (try removing the *s in C or the POINTER attribute in Fortran and it will fail to compile). This is because types, much like arrays, are laid out contiguously in memory so they can only contain things that the compiler knows the length of and if you have a type that contains an instance of itself then there would be an infinite regression problem because you don't know how big it is until you have finished creating it and you can't create it until you know how big it is. Pointers are all of a fixed size so they work OK.
The structure as given is for what is technically called a doubly linked list because it contains links both to the next item and the previous item in the list. A singly linked list has each item linked only to the next item in the list. Doubly linked lists have some substantial advantages over singly linked lists, notably that you can go through it from either end, but also you can remove an item from the list needing only the item itself (and the list that it is held in if you have several).
Creating linked lists
Creating a linked list is quite easy. You hold a simple pointer to the first element in the list (generally called the head item) and then you simply create the list going down from that. The key thing is that you have to hook up the prev and next links as you go. This isn't too difficult and looks like
#include#include struct llitem{ int value; struct llitem *next; struct llitem *prev; }; void init_ll(struct llitem * l) { l-> value = -1; l->next = NULL; l->prev = NULL; } int main(int argc, char** argv) { struct llitem *head, *current; int i; head = malloc(sizeof(struct llitem)); init_ll(head); head->value = 1; current = head; for (i=0;i<10;++i){ current->next = malloc(sizeof(struct llitem)); /*Create the next element*/ init_ll(current->next); /*Initialise it to nullify pointers*/ current->next->value = current->value + 1; /*Simple counter*/ current->next->prev = current; /*It's previous pointer should be the current item*/ current = current->next; /*Now move onwards so the newly created particle is now current*/ } current = head; while(current){ printf("%i\n", current->value); current = current->next; } }
PROGRAM test
IMPLICIT NONE
TYPE :: llitem
INTEGER :: value = -1
TYPE(llitem), POINTER :: next => NULL()
TYPE(llitem), POINTER :: prev => NULL()
END TYPE llitem
TYPE(llitem), POINTER :: head, current
INTEGER :: i
ALLOCATE(head) !Create the head
head%value = 1
current => head
DO i = 1, 10
ALLOCATE(current%next) !Create the next element
current%next%value = current%value + 1
current%next%prev => current !The next element's previous is the current element
current => current%next !Now move onwards so the newly created particle is now current
END DO
current => head
DO WHILE (ASSOCIATED(current))
PRINT *,current%value
current => current%next
END DO
END PROGRAM test
This example also shows how you how to step through the linked list from the head, simply by having a "current" pointer that starts at head and is then incremented by setting current = current->next (or current => current%next in Fortran). This can look a bit odd but it isn't that hard to understand. I start by manually creating the "head" element, using either ALLOCATE or malloc. Once I have a head element I then loop through, each time using the same ALLOCATE or malloc command on the "current->next" pointer, creating a new item every time. In C I then call the ll_init function to setup the values of the struct (in Fortran this is done for me since I gave the elements of my TYPE default values). After this the prev and next pointers are both NULL. This is correct for the next pointer becuase my new item is the last item in the list (it won't be next iteration but right now it is), but I have to set the prev pointer. If my new item is the next element in the chain from my current element then the previous element in the chain from my new element must be my current element so I set that up. After that I just have to repeat until I have added enough items.
Part 2 of this will be in a couple of weeks and will describe how you remove and item from a linked list and how to add new items to the middle of a linked list.
 Christopher Brady
15 May 2019 17:20
|
Christopher Brady
15 May 2019 17:20
| ![]() Tags: Code Programming
|
Tags: Code Programming
|  Comments (0)
|
Comments (0)
| 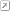 Trackbacks (1)
|
Trackbacks (1)
|  Report a problem
Report a problem
 Please wait - comments are loading
Please wait - comments are loading
October 03, 2018
Pretty please print
The possible impossible
A pretty short entry this week, on a likely familiar theme. You have some buggy code. You try and trace the bug by inserting 'print' statements. Eventually you have prints wrapped around the troublesome piece and you may find yourself saying something like:
Aha! It reaches line A, but never line B! But thats IMPOSSIBLE! There's nothing there but simple code that can't just not execute! In fact there's only blank lines!
As usual, once you find yourself uttering a line like that, it's time to step back. Computers only rarely do the impossible.
Many things can have happened here, but a common, very confusing one, is that the second print has run, but you're not seeing the result. This is common because most languages default to bufferredoutput to stdout. We mentioned this a little bit in context of output streams in a previous entry, here we give a bit more detail.
Aside - stdout
If stdout and stderr aren't already familiar, they are the short names for standard out and standard error. There's a little bit about those herebut basically they are the designated way of writing output (information) and errors to the terminal. They're separate because sometimes you only want to see one or the other. You can direct them to separate files if you want (see the link for how). It is very good practice to respect the designation, and use the correct stream when you write information. It's acceptable to write everything to stdout in your code, but you really shouldn't be writing anything except actual errors to stderr. Warnings are acceptable, but only if they're "important". Save it for things that a user really needs to know.
Back to the Print Problem
The conversation goes something like this:
"So, what's going on with my prints? If it's printing but I don't see it, where is it?"
"It's in an output buffer, waiting until there's enough stuff to be worth printing. "
"Hang on, worth printing? I think it's worth printing! Print it!"
However, there is a good reason. The easiest way to show this is with some code. The following Python3 code uses both buffered output and unbuffered output where we force each print statement to flush the buffer so each print happens exactly as it is reached:
import time
_iters = 100000
def many_prints(flush):
for i in range(0, _iters):
print(i, flush=flush)
start_time = time.time()
many_prints(False)
timef = time.time() - start_time
start_time = time.time()
many_prints(True)
timet = time.time() - start_time
print("No flushing --- %s seconds ---" % timef)
print("Flushing --- %s seconds ---" % timet)
Run this a few times and you should see that flushing is slower. It's not always by much, but it can be 20%, or more, depending on system, which is sometimes significant.
Why so Slow?
So why is unbuffered output slow? In this case, mainly because interacting with the terminal and redrawing the screen takes time. Writing to a file can be even slower, because now we have to interact with the file system and disks, and maybe even wait for a success signal to come back. It's much better if these events can be collected into larger bursts, so we only have to do that rigamarole once.
Unbuffered Output and Flushing Options
We showed Python3 above, where we can simply use the flush Keyword. In Python 2 we have to do a little more. This linkshows the main options. We can force the Python interpreter to not use buffering at all, or we can override it for given output streams. Or we can write custom objects that flush exactly when we want.
In Fortran, we just call the FLUSH subroutine either on all outputs or the unit of our choice.
In C, we can flush stdout with fflush, set stdout to be unbuffered, or use stderr which is unbuffered by default.
In C++ there is a slight wrinkle as we can use either C-style IO via stdio, or C++ streamio. std::endl is a command to flush the output stream, not just a new-line, so it's usually recommended to use `'\n' to get just a newline, and std::endl only when required.
C++ IO
While we're here, we should mention on thing about mixed IO in C++. By default, a program can mix stdio via printf and stream-io (using <<), and similarly for input. BUT these two methods have to be force to share any buffering, or else the would not work together. This means they are forced to stay in sync, so inputs and outputs work as expected. In some circumstances, especially if a lot is written to stdout, it may be useful to only use one or other of these, and disable the syncing. See here for details, but be very very careful.
Bottom Line?
The bottom line of all of this is pretty simple. When doing print-style debugging, or printing error messages, either use stderr (making sure that's not buffered in your language or system), or flush after every essential stage of your prints, or disable buffering completely while debugging. You don't need all three. And finally, remember the golden rule. If it looks impossible, you're probably assuming something that isn't true. Not terribly snappy, but a useful thing to remember.
Heather Ratcliffe
03 Oct 2018 21:16
| ![]() Tags: Code Debugging Io
| Comments (0)
| Report a problem
Tags: Code Debugging Io
| Comments (0)
| Report a problem
September 05, 2018
Data structures 2 – Arrays Part 2
Part 2 of arrays is about dynamic (run time) sized arrays. That is arrays where you don't know how large they're going to be until the code is running. First, I'll go through it in Fortran because it is really easy in Fortran, and powerful array operations are one of the major advantages of Fortran.
Dynamic arrays in Fortran are generally called ALLOCATABLE arrays (there are also POINTER arrays, but they are generally harder to use for only fairly specific benefits), and you declare them pretty much the same way that you declare any array in Fortran
INTEGER, DIMENSION(:), ALLOCATABLE :: myarray
You then allocate it using
ALLOCATE(myarray(0:100))
First, note that the DIMENSION(:) syntax in the variable declaration is the same as when you're passing an array to a function where you don't know how big the array is. This is the general way of telling Fortran "I don't know what size this is until runtime" (there are a few features where it's * instead for things like the length of strings, but in general it's :). Also note that I have explicitly allocated the array bounds, with the array running from 0 to 100 inclusive. If I'd just used
ALLOCATE(myarray(100))
then the array would have run from 1 to 100 inclusive. In Fortran you can have any upper and lower bounds for arrays that you want which is sometimes useful. You do have to be careful though because unless you are careful when you pass arrays into functions these bound markers are ignored inside the function and the array just runs from 1:n.
Moving to multidimensional arrays in Fortran is easy.
INTEGER, DIMENSION(:,:), ALLOCATABLE :: myarray
ALLOCATE(myarray(0:100, -1:101))
myarray(10,10) = 1
will create a 2D column major array with the array bounds that I specified in my allocate statement. Job done. Fortran ALLOCATABLE arrays also have the nice property that they are automatically deallocated when they go out of scope so it's much harder to have memory leaks with Fortran ALLOCATABLE arrays (you don't have this guarantee with POINTER arrays because this doesn't make use of reference counting and garbage collection. It relies on the fact that there can only be a single reference to a Fortran allocatable.). If you want more control over when memory is returned to you then you can also manually DEALLOCATE the array
DEALLOCATE(myarray)
Before I start on the C section, I should note one thing: C99 and later standards do define variable length arrays (usually referred to by the acronym VLA). They aren't really very common in scientific code and they have all sorts of oddities about how you use pointers to them and where you can and can't use them (you can't have them in structs for example). Given their general rarity and strangeness (and the fact that they aren't valid in C++ before C++14) I'm not going to talk any more about them, but they do exist and you might want to look them up if you're writing a new code in C. 1D run time arrays in C are traditionally created using the "malloc" memory allocation function. You tell malloc how many bytes of memory you want and it creates a chunk of memory that long and hands you a pointer to it. The syntax is easy enough
#include <stdlib.h>
int main(int argc, char **argv){
int * myarray;
myarray = malloc(sizeof(int) * 100);
myarray[0] = 10;
free(myarray);
}
Note the use of the "sizeof" operator to find out how many bytes are needed to store an integer. If you want to write code that works on multiple machines you'll have to use this because integers are not always the same size. In most senses you can consider a pointer and a 1D array to be very similar in C. When you use the square bracket operator you get the same element of your array in both cases, and in fact the layout of the memory behind the scenes is conceptually similar (although if you want to be precise a static array will generally be allocated on the stack, while malloc gives you memory from the heap). Also, note that I have used the function "free" to delete the memory when I am finished. If I don't do this then there will be a memory leak. C explicitly does not keep track of memory at all. Sadly it gets rather harder in multiple dimensions.
malloc always gives you a 1D strip of memory, and there is no equivalent function to give you a multidimensional array in standard C. My preferred solution is just to allocate a 1D array and then use an indexing function to access the element that you want. For example
#include <stdlib.h>
int main(int argc, char **argv){
int * myarray;
int nx, ny; /*Size of array to be filled somehow*/
int ix, iy; /*index of element to access to be filled somehow*/
myarray = malloc(sizeof(int) * nx * ny);
myarray[ix*ny + iy] = 10;
free(myarray);}
This will work perfectly and will give pretty good performance. Usually you'd write some kind of helper function or macro rather than having ix*ny+iy all over your code, but this shows the general technique. You do have to be careful writing your index function though because [ix*ny + iy] gives you a row major array and [iy*nx + ix] gives you column major. This can be useful but you need to be sure what you're doing. The other problem with this is that you can't just access your array as if it was a compile time multidimensional array. If you try to access this using myarray[ix][iy] you will get a compile error. This is because behind the scenes the [] operator dereferences your pointer with an offset (you can replace myarray[ix] with *(myarray+ix) if you like pointer arithmetic). Because of this when the first square bracket has happened you are just left with an integer, so the second square bracket operator is an invalid operation. So can you keep the multidimensional access? Yes, but there are always downsides.
#include <stdlib.h>
int main(int argc, char **argv){
int **myarray;
int nx, ny; /*Size of array to be filled somehow*/
int ix, iy; /*index of element to access to be filled somehow*/
int ind; /*Loop index*/
myarray = malloc(sizeof(int*) * nx);
for (ind = 0; ind<nx;++ind) myarray[ind] = malloc(sizeof(int) * ny);
myarray[ix][iy] = 10;
for (ind = 0; ind<nx;++ind) free(myarray[ind]);
free(myarray);}
This works by making myarray a pointer to a pointer to an int (int **myarray). You then allocate the outer pointer to be an array of nx pointers to int (note that my first sizeof is now sizeof(int*), not sizeof(int)!). You then go through all of these pointers to integers and allocate those pointers to themselves be ny element long arrays of integers (note that the second sizeof is sizeof(int)). This will work as expected, and you can now index your array with square bracket operators as normal, so what's the problem. The problem is that malloc doesn't give any guarantees about where the memory that you get back from it is located. In this simple test case the memory that you get will probably be layed out in a contiguous block, but in general this won't be true. By splitting your memory allocation up like this you are potentially creating a memory prefetch problem much like the one that you get by accessing an array in the wrong order, with similar effects on performance. There is a fringe benefit for this type of array : because the rows are allocated separately they don't have to be the same length as each other. It's tricky to make use of this property (because you have to keep track of how long each row is yourself) it can be very powerful for certain types of problem. On a related note you will often find that multidimensional arrays in C++ are created using std::vector<std::vector<int>> types. This in general has the same type of problem with memory not being contiguous, as you can clearly see from the fact that you can push back into each vector individually.
The final solution is to create a 1 dimensional chunk of memory and then rather than using an indexer function use a separate list of pointers to the start of the row. There are lots of ways of doing this, and this example isn't a terribly clever one but it does work
#include <stdlib.h>
int main(int argc, char **argv){
int nx = 10, ny=10;
int ind;
int **myarray;
int *buffer;
myarray = malloc(sizeof(int*) * nx);
buffer = malloc(sizeof(int) * nx * ny);
for (ind = 0; ind< nx; ++ind) myarray[ind] = &buffer[ind * ny];
myarray[5][5]=54;
free(buffer);
free(myarray);}
Christopher Brady
05 Sep 2018 17:18
| ![]() Tags: Code Programming
| Comments (0)
| Report a problem
Tags: Code Programming
| Comments (0)
| Report a problem
July 30, 2018
Committing Sins
A short one again, this time about commit messages. Some of this, particularly the message formats, is specific to Git, but the rest applies to any version control system, even the trivial one of saving a timestamped version of code files.
What I say here has been said many times, but it always bears repeating, because things like this don't matter... until they do, and you're rummaging through weeks of messages looking for some key word you don't recall and trawling through endless useless messages that only say "Fixed a bug" or "Cleaned up code". Having a code history is only useful when you come to use it, usually when something has gone a bit wrong, at which point you want concise, meaningful and absolutely correct data.
The Unwritten Rules
First, there are some simple rules on how a git commit message should be formatted, that are a bit hard to find written down, although some editors like Vim will highlight commit messages according to them. They are noted in the Discussion section of the man page for git-commit too and are discussed here. The expanded rules are:
- Follow any specific rules for a particular project first!
- The first line is the subject, and should be less than 50 characters.
- The second line must be blank. Any text here is ignored.
- The subsequent lines are the message body, and should generally be less than 72 characters.
- Use as many lines as you like, but be concise. If you need paragraphs, put blank lines between them
- If your code uses an issue tracker, include reference numbers for connected bugs etc
- Explain why, and what in the broad sense (see next section)
DRYness and Wit
Next, one of the overarching themes in programming is 'Don't repeat yourself' (DRY). As soon as information appears in two different places, you risk them becoming out of sync, and double the work of changing or understanding the thing. I talked about this a bit in the last post under the banner of "self documenting code". There, the idea is to let the code speak for itself, rather than trying to explain it with comments, saving your comments for the 'whys' and the information not available this way. Commit messages are the same. Anybody can look at the changes you made to the code, and know what precisely you did. The message is your chance to tell them why you did this, how this fixes a problem or what was wrong.
XKCD has a comic on this (he always does) and there are many humoroussites, some ruderthan others, as well as endless blog, forum and user guide entries with their own ideas about what is best. I like to mention once again the 'Principle of least surprise'. Make sure your code does nothing surprising in light of your message. For instance, NEVER commit something with message"Whitespace changes" if it does other things too!
Making History
Finally, there is the question of how large, how contained and how functional commits should be. As usual, there are as many theories about this are there are programmers. Some like to commit little and often, and before sharing that branch with anybody, squash togetherchunks into logical blocks. Some consider that to be a forbidden sort of rewriting of history. There are many, many ways to manage your work, and few rules. But:
- Alwaysfollow any guidelines for the project you're working on first and foremost!
- Anything you share should compile (if relevant) and run, although it needn't work in all respects. Otherwise, tracking when a bug was introduced can be a nightmare, particularly once your part-working code is merged with somebody else's and the result does what neither of you expected. See below for more.
- A large feature should probably be spread across several commits - building it up piece by piece.
- What you share should make sense. It's OK to try things out, find they don't work, and go back, but you probably only want that to be part of the history if its useful in showing why it didn't work.
Note: There is a crucial difference between code which is written to not work, and code which doesn't work. The former is things such as a function called 'is_thingy' always returning 'false'. The latter is that function returning something undefined (in fact, one release of the GCC C compiler had exactly the former for its regular-expression parsing code, always returning no-match). However it is usually acceptable for such a function to return an error, or throw an exception, because the calling code can handle that.
Summary
There's nothing in here that hasn't been said many times before, but the real take away is pretty simple - whatever strategy for messages, comments and code style, it should always be about increasing what you know about the code, not repeating it!
Heather Ratcliffe
30 Jul 2018 11:48
| ![]() Tags: Code Docs Git
| Comments (0)
| Report a problem
Tags: Code Docs Git
| Comments (0)
| Report a problem
July 11, 2018
Maths in Code
Programming Equations
Short post this week, with a simple theme: how should you translate equations into code?
Self Documenting Code
Self-documenting code (aka self-describing code) is code that documents itself, rather like the term 'self-documenting code' already tells you what it means. The idea is to choose function names, variable names and types, and (in relevant languages) Class or Object hierarchies so that they demonstrate what they do. This can mean a lot of things, and tends to mean slightly different things to different people. In general, especially in cases of ambiguity, one aims for the "principle of least surprise" - what is the least unexpected meaning of something with this name? For instance, old fashioned C programmers, might consider "i" to be a perfectly self-documenting loop variable, as the usage is very familiar.
This leads us nicely into the spirit of self-documentation. Programming is hard. Choosing sensible names and structures reduces the effort needed to keep track of what things are, as well as everything else in your program. This means that the names you choose should help you, and whoever reads or uses your code, work out what things mean. Imagine coming back to your code after weeks or months not working on it. Can you read it through and guess, correctly, what things mean? If not, consider reworking your namings or structure.
Names shouldn't just repeat information already available though, as that wastes space which could be better used. For example, a boolean or Logical variable already tells you that this is probably some sort of flag, controlling whether or not something should happen or has happened. "write_to_file" is a useful name. "flag" is not. "is_open" is a useful name for a flag associated with a file, "open_flag" is rather less so.
On this note, there is a common naming scheme which uses so-called Hungarian Warts, where some sort of 'type' information is prepended using a few (< 3) letters. Originally these were used to add 'extra' information, such as 'us' for 'unsafe string', which can be very useful. In languages like Python, where definitions don't specify type info, even just tages like 's' for string can be useful, as long as you make sure this is actually true!
Don't go mad with descriptions though. Supposedly the average person can keep 7 things in mind at once so you definitely don't want to occupy all that space with your variable names. 2 or 3 pieces is about the limit for most names, so try and use things like "input_file" not "file_to_read_data_from" and avoid linking words as far as practical. Keep names short and sweet, to save typing and brain-space.
By the way, if you use an IDE to program, you might feel that none of this matters, but while it will fill in the names for you, it really doesn't solve everything. You still need to keep track of which variable you want and select the correct one in ambiguous cases, and keep track in your head of what is what. The self-documenting ideal means that when your IDE gives you a list of 5 similar looking variables, you barely have to think to select the one you need in context.
Self Documenting Equations
Take a nice simple equation, ax^2 + bx + c = 0 and imagine programming something to solve it. If you took the self-documenting advice at face value, you might convert "x" into "polynomial_variable", and "a, b, c" into "coefficient_of_square_term", "coefficient_of_linear_term" and "coefficient_of_constant_term". That leaves the quadratic equation looking pretty complicated, as
polynomial_variable = (- coefficient_of_linear_term +|- sqrt( coefficient_of_linear_term^2 - 4 * coefficient_of_square_term * coefficient_of_constant_term) )/ (2 * coefficient_of_square_term)
instead of the far more familiar
x = (- b +|- sqrt( b^2 - 4 * a * c)) /(2 * a)
Similarly, if you program equations from a paper, it can be much, much easier to use variable names that match the paper, especially when trying to verify them. Sometimes it is even a good idea to mimic the paper's equation format, at least until things are working. More on that in the next section.
Optimising Equations from Papers
So what about rearranging equations for optimisation purposes? If you ask ten different people, you'll get ten different answers, but in my opinion the following are the keys:
- Only simplify once the code works. Don't bother collecting, hoisting or other tweaks until you need to.
- Keep names generally the same as the paper, but ideally remove ambiguity, so don't use 'a' as well as 'A'. Consider 'a' and 'bigA' for more distinction. Absolutely avoid ambiguities like 'l' and '1'.
- When you do change to rearranged equations, consider leaving the original code present in a comment. This is one of the few places where commented code is a good thing.
- When you combine or collect terms, start by just combining their names or the functions use, so use 'A_squared', 'sin_theta' or 'A_over_B'
- Include a link to the paper or source you used in the code, so that your variable names remain useful. Somebody with a source that uses different namings will find this style really tricky. If you can, consider including a snippet in your docs detailling the original equations and what rearrangements you did.
Find your style, stick to it, and optimise only as much as necessary to get the performance you need!
Mathematica for Complicated Expressions
If your equations need substantial rearranging or simplifying, you might turn to a tool like Mathematica to do this for you, but did you know that it can even write C or Fortran code directly?
https://reference.wolfram.com/language/tutorial/GeneratingCAndFortranExpressions.html
You can save a lot of typing, and avoid some really easy mistakes by taking advantage of this. Don't forget FullSimplify and to apply suitable restrictions on variables to get a nicer expression before doing this though.
Heather Ratcliffe
11 Jul 2018 11:20
| ![]() Tags: Code Mathematica Programming
| Comments (0)
| Report a problem
Tags: Code Mathematica Programming
| Comments (0)
| Report a problem
June 13, 2018
Fix Me
Fancy Latex Customisation
Writing up notes and papers, I often find that I want to leave myself reminders, hints and other snippets that I'd rather didn't make it into the final draft. Or I want to collate notes from throughout my text into a file I can put in my appendix, such as a list of future work. I often think of Latex as just a typesetting language, but Tex itself is actually a fully Turing complete language and Latex isn't too far off. The hardest bit of Turing completeness is usually the ability to do conditional branches which Latex can do with a bit of work. Thankfully there's a common package that takes some of the load off us.
NOTE: many journals wont accept manuscripts containing custom commands, so don't forget to remove your commands from papers you submit in future.
The Latex snippets are available on our Github page and are described below in more detail.
Defining Latex Commands
Firstly, we use the Latex \newcommand to do some custom formatting we can easily vary, in this case to make our text bold. \newcommand is fairly simple. The syntax is
\newcommand{\<name>}[<n_args>]{<command>}
where the parts in <> should be replaced with appropriate text. Thist creates a command called "name", taking "n_args" arguments and applies "command". The arguments are referred to using a '#' within your command, as in the following example where we feed the text inside the \fbrtext braces into \textbf.
\newcommand{\fbrtext}[1]{\textbf{#1}}
If there are no arguments, you can omit the [<n_args>] part entirely.
We can define as many commands this way as we like, but they must not be already defined. To redefine something, use \renewcommand (but carefully, making sure not to clobber something important like \section).
Collating Snippets with Output Streams
The first snippet is to collate some things into a file so we can review things we'd like to fix or add to our document before we release it. Snippet 1 is a simple Latex document which does this. We put the commands in a .tex file named ReleaseFixes, and include this into our main document, so that we can reuse it easily.
The core part of this is a package called "newfile" which allows you to write to files as the Latex compilation runs. This is how things like index and glossary packages work at heart, creating a temporary file that can then be included. This package lets us create "streams" for output, that we can write to, which may be familiar from Java, C++ or other languages. We name our stream "releasefixes", and then open a file to which it should output.
Now we create the main command, which takes one argument, a text chunk. This chunk will appear in our document in bold red text, and will also appear in our output file. In the output file, it'll show the line number (in the input .tex file) where the text appears. We could also include the page number in the output pdf if we wanted or other such useful commands.
Including Snippets into our Document
Perhaps we want to include the snippets we've generated into an appendix, so that we can send the draft to somebody else and they have a handy list of all the changes we want to make, or things we need filling in. Or maybe we want to use a similar command to list the changes we've made to a draft for easy review.
In Snippet2 we adjust our command so that rather than creating a simple text file, we put a '\item' command at the start of every item. Then we add a section to our document, and include the file we generated, inside an \itemize environment. This should give a neat bullet-pointed list of things to fix.
This doesn't quite work yet: the stream seems to be empty at the point where we read it, even though the file is complete when we look afterwards. When you have an unexpectedly empty output file it is usually because the stream didn't get "flushed". Flushing an output stream means moving its contents from a buffer in memory to the actual output file. This could be done every time we write to the stream, but if we do lots of tiny writes it is much slower this way than waiting until we have "enough" and writing in a chunk.
Normally, output flushing happens when the compile ends and everything gets closed, but we want access to our file before this. So we insert an explicit \closeoutputstream in just before our new section to write the file immediately, and then we can open it for input. We include its contents, and they are then typeset just like a static included file.
Using ifthen to Typeset Variants
Suppose that rather than showing us the changes, we want a way to include or exclude them from the output file entirely. This is really easy to do with a quick edit, because we just redefine our \fbr command to omit the text instead, and compile again. Easy for one command, but what if we have several things we want to change for our "draft" mode? It's tedious and error prone to edit them all.
A perfectly good solution for this precise case, by the way, is to create two versions of our "ReleaseFixes.tex" file, one for draft mode, and one for release mode, and edit our file to swap between them
\include{ReleaseFixes_draft.tex} %Swap with next line for release
%\include{ReleaseFixes_release.tex}
However, this is a good demonstration of conditionals, so let's try that. In Snippet3 we use the package "ifthen" which provides an "ifthenelse" command, that looks like
\ifthenelse{<condition>}{<command if true>}{<command else>}
The package allows us to define boolean flags. We define one called usered which chooses whether our text should be output in bold or red-bold.
However we can only define flags after we've include the package, and we'd prefer the draft mode selection it in our main document. So we define a normal command, \draft, and check if this is defined instead. We adjust the \fbr command to do nothing in release mode (\draft not defined) or to give us bold text (red if the flag says so) and a file entry in draft mode. Then by un/commenting line 6 of Document.tex we control the final form.
Summary
Latex typesetting gets a lot easier once you have a few simple commands at hand. It gets a lot more powerful once you add the ability to do conditionals. "Clever" commands like this should be used with caution, since anybody who wants to compile the document needs the relevant packages, but they are very handy when you need them, and can save a lot of time and effort. And do remember that you'll probably have to remove anything like this if you submit Latex to journals.
Heather Ratcliffe
13 Jun 2018 14:43
| ![]() Tags: Code Docs LaTeX Soup
| Comments (0)
| Report a problem
Tags: Code Docs LaTeX Soup
| Comments (0)
| Report a problem
May 31, 2018
More randomness and a bit of non–randomness
Normally distributed random numbers
The last blog post was about getting high quality, uniformly distributed random numbers. In this post, I'm going to address the question of what to do if you want to have non uniformly distributed random numbers, that is random numbers where some are more likely than others. One of the ways that we're going to be looking at this is by looking at Probability Distribution Functions(PDF). These graphs are very like histograms, but they instead say "I have a source of random data U. For the entire source U, what is the probability that any given value is in the range x to x + dx, where dx is a finite but usually small deviation from x". In practice, what you do is you split up the range of U into a series of bins of width "dx" and then just count the number of particles in each bin and divide by the total number of particles.
The above graph shows the probability distribution for a uniform random number when you have 1,000 bins between 0 and 1. This number of bins explains why the graph is showing a rough line centred around 0.1% probability. Since a uniform random number generator should produce values in all bins equally, you would expect (100/nbins)% (so 0.1% for 1,000 bins) to lie in each bin. The graph shows that the random number generator that I'm using is working reasonably well.
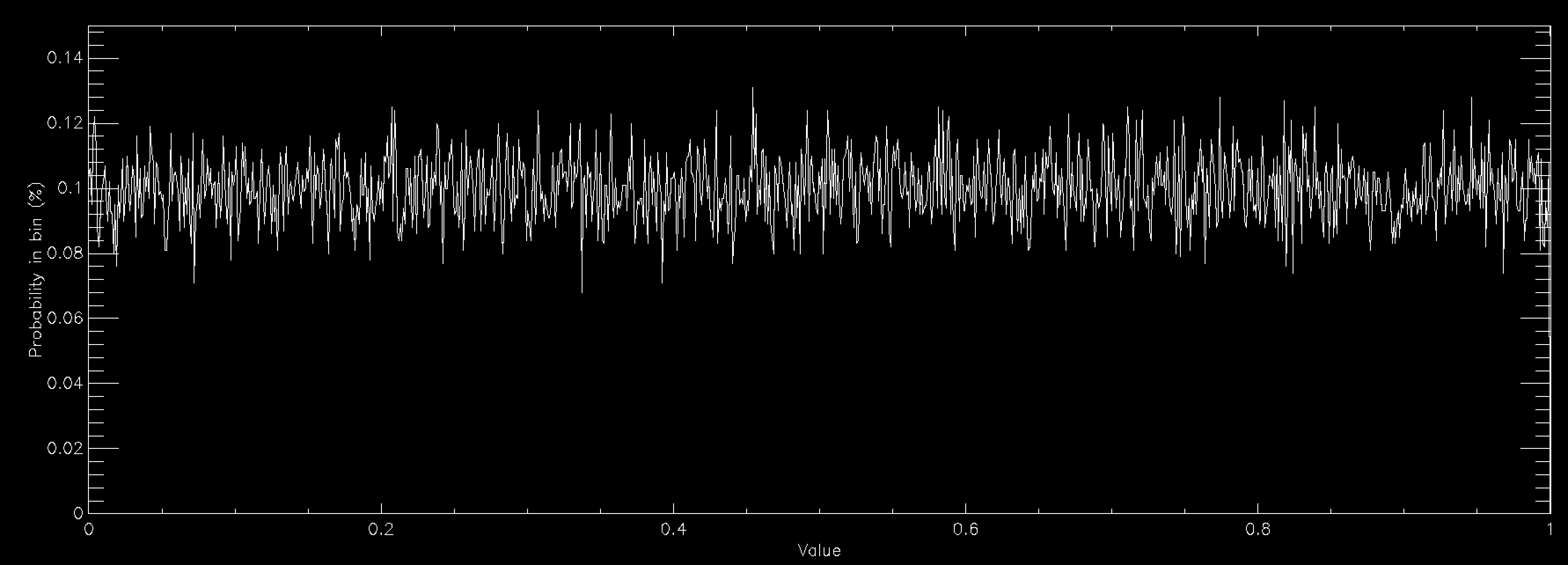
This graph shows the same thing for a normally distributed random number (also called Gaussian, or in some fields Maxwellian distributions and sometimes bell curves). It is strongly peaked at zero and extends out to ±6. Normal distributions are very important in many areas of study (see here for some examples), and is found in things as diverse as the distribution of speeds of particles in a gas to the distribution of heights of members of a sports club. As a consequence there is a lot of interest in generating normally distributed random numbers. This is often called "sampling" the distribution. The graphs above were created by getting random numbers and counting how many fell into each bin on the graph, but often you want to go the other way. You want to draw the graph and then get random numbers such that their distribution will match the graph.
Fortunately there's a very easy way of converting from a uniform random number generator to a normally distributed random number generator via an algorithm called the Box-Muller Transform. I'm not going to go into the maths of it which are detailed on the linked Wikipedia page, but if you want normally distributed random numbers the Box-Muller Transform is your friend (usually the specific variant called the Polar Box-Muller Transform). Lots of languages already have built in implementations of normally distributed random number generators, generally using that transform so it's worth looking for those first, especially in compiled languages like Python where the built in function will probably be much faster than yours. However, in languages like C or Fortran which don't have a built in one you probably want to find or write an implementation of the Box-Muller Transform if you need normally distributed random numbers.
Arbitrary distributions in one variable
Sometimes, however, you have a more complicated distribution function that you want to sample. Sometimes there are other transforms like Box-Muller, but quite often there aren't. At which point the most powerful tool you have is called Inverse Transform Sampling. This introduces a new idea the Cumulative Distribution Function (CDF). The CDF is very much like the PDF in many senses, but instead of saying "how much of U is between x and x+dx" it says "how much of U is between min(U) and x", hence the cumulative in the name. It is the accumulation of the probability of the value being at x or lower.
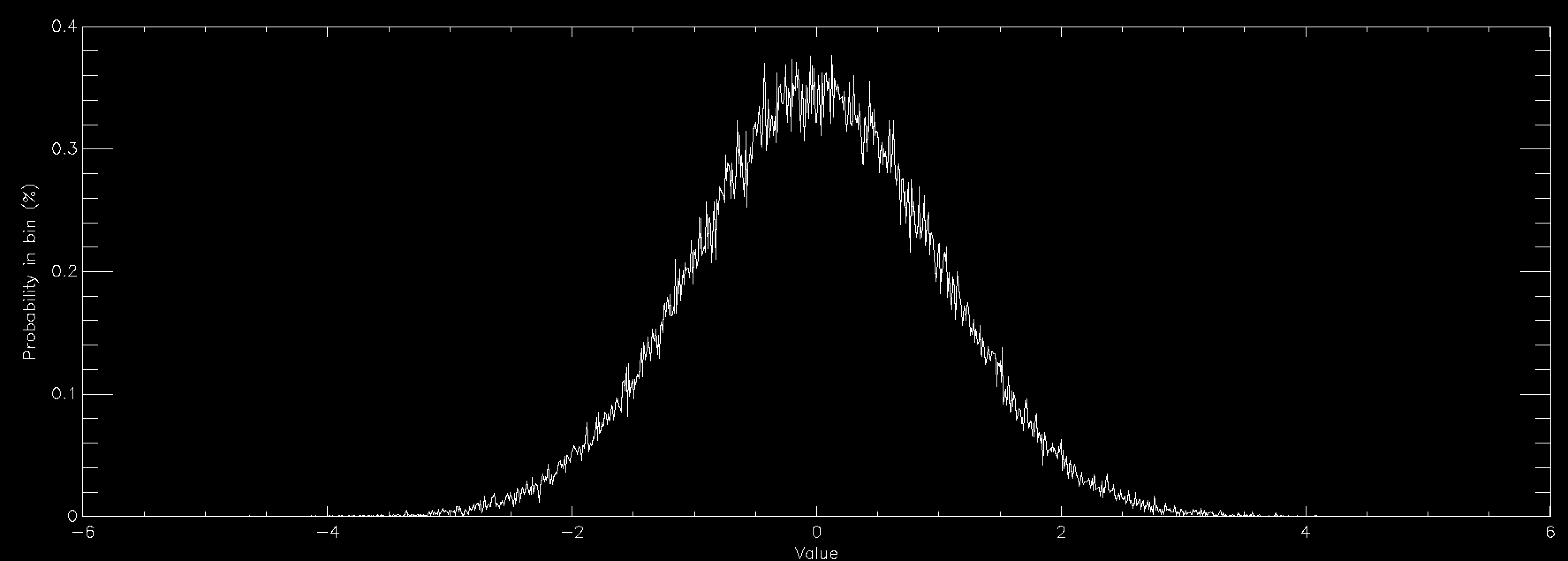
The graph this time compares the PDF (left) to the CDF (right) for a normally distributed number. The CDF has a value of 100% at the right because everything has to be less than the largest value. You can create the CDF in a number of ways, but on a computer a very common way is to define a grid of values (x(i), say) and calculate the PDF (PDF(i)) for each of them. This does mean discretising your distribution but that is often sufficient and you can often interpolate the result. The CDF is then simply defined by
CDF(i) = SUM(PDF(0:i))
where i is the index into a zero based array and is evaluated from 0 to n, where n is the number of elements in the array.
Once you have the CDF sampling it is surprisingly easy. You simply pick a uniform random number between 0 and 100 and then find out which value of i is the cell in which the CDF exceeds that value. You then have sampled the value x(i). You keep repeating this until you have sufficient values. If you then check the distribution of the values it will match the PDF that you specified. Effectively this divides the PDF into bins of equal area under the curve, and selects one bin at a time with equal probability. On the CDF graph, equal area bins correspond to a uniform division of the y axis.
The actual implementation of this can be a bit messier because while the easiest way of finding which cell of the CDF exceeds your random value is simply to start at i=0 and count up, the fastestway is to use binary bisection on the index. This works because the CDF is guaranteed to increase from left to right, so if you pick any point you know if the point that you want is to the left of that point if the value is smaller and to the right of the point if the value is larger. So you can keep dividing the space into sections until you have found the value that you want. But that is an implementation issue rather than a conceptual one.
Note also that if you can integrate the PDF to obtain a CDF, which you can then invert, you can do all of this analytically, but even simple PDFs like a Normal distribution don't have an invertible CDF.
Distributions in more than one variable
Distributions in more than one variable can be tricky. But if the function is separable, that is it can be written as two functions multiplied together, each of which is in a single variable (f(x, y) = g(x) * h(y)) each part can be sampled as above. For each complete sample you take one random sample of the function g, and one of h, and multiply them together.
Functions in more than one variable which don't break down like this are generally treated using a technique called accept-reject sampling, or some more sophisticated technique in tricky cases. More on this next time.
Christopher Brady
31 May 2018 11:55
| ![]() Tags: Code Programming Randomness
| Comments (0)
| Report a problem
Tags: Code Programming Randomness
| Comments (0)
| Report a problem
May 02, 2018
Hierarchies of Git(s)
Version Control and Git
Version control of some sort is essential in a software project. Suppose you make a change and your code no longer works - how can you go back? Suppose you find something you don't understand - who made that change? If you publish work using a code, can you recover the exact state at a later time? While carefully maintained records can go a long way, these exact problems led to the development of sophisticated version control systems which could do these things almost automtically. One of the most popular systems in use now is named 'git'.
For a basic rundown of version control, git, and why and how to use it, we have some notes here. This post is a (very brief) introduction to a useful but relatively uncommon feature, git submodules.
The name git, by the way, is no coincidence. It is a handy, pronounceable, 3-letter combination, that wasn't already in use for any Linux utilities, but also a convenient descriptor for the project creator, Linus Torvalds of Linux fame.
Great Fleas have Smaller Fleas
On one occasion we had a request for support in which a user was getting a cryptic error messages about `fatal: bad revision 'HEAD'` when attempting any git commands in any directories. In particular, he was unable to build our code because it used a `git describe` to obtain version information. After a bit of digging, we were able to work out that somewhere in a directory above our source code, he must have run a `git init` command.
This left our git repository in a invalid state and most git commands unusable. The user recalled typing the command, but not where he did it, so first we had to find the bad directory level. Since commands were failing, we could simply work upwards one directory at a time running `git describe` until we instead saw `fatal: Not a git repository (or any of the parent directories)`. A better solution is to use the command `git rev-parse --show-toplevel` which displays the current top-level git repository name.
Running this, it appears he had managed to do this in his `home` directory, leaving any and all git repositories among his files in this state. Thankfully the final remedy is simple: remove the invalid git directory by simply deleting the `.git/` folder at the wrongly initialised level. Much easier than feared!
Submodules
The proper way to have this sort of nested git project is using a relatively uncommon feature called submodules. These are separate git projects which can be imported and used, and are commonly used for deeply embedded library code. A submodule is a repository in its own right and can be checked out alone, and work on it should generally be done separately in this way.
For most people their only encounter with submodules will be the following two commands. When cloning a project that uses them, clone all submodules also using:
git clone --recursive [repo]
When making and removing small, temporary alterations within the submodule, some times when the submodule changes in the repository you cloned from, or any time you see a message like
-Subproject commit abc123xyz +Subproject commit def456uvw
in a git diff, the command:
git submodule update --recursive
will update all submodules to their current versions. The 'recursive' flag ensures all submodules, including any within other submodules, are updated.
But What Actually Are Submodules?
Basically, a submodule is a separate repository, connected to the main project. This connection is via a single commit, and a submodule within a main project is in a detached-head state. As of git 1.8.2 submodules included in a larger project can specify which branch of the submodule project to link to.
For all the gory details of working with submodules, see resources such as
https://www.git-scm.com/docs/gitsubmodules
https://git.wiki.kernel.org/index.php/GitSubmoduleTutorial
and https://blog.github.com/2016-02-01-working-with-submodules/
For now, you can think of them as a way to include 'library' type code which is under active development into several other projects and also allow it to stand alone.
Rescuing a Bad Chain
Sadly it is not particularly difficult to make a small alteration in a submodule (such as temporarily amending a compiler flag) and find yourself with a main repository insisting that there are uncommitted changes in the submodule, or worse, an unexpected detached head somewhere. Don't lose your head over this (sorry). Sometimes the submodule update command is all you need. Other times you will have to reset all the directories. First, commit or stash any changes you want to keep! Then the command
git submodule foreach --recursive git reset --hard
will remove all changes in all submodules, and a final
git submodule update --recursive
should put everything back to normal.
Summary
Git submodules are a powerful, sometimes tricky feature, which basically allow the inclusion of shared code into several other projects while also letting it to stand alone, to be released as a library and/or developed as a separate project. If you encounter submodules it will probably be as simple as somebody's repo needing to be cloned with the --recursive flag. To contribute to the submodule, clone it and only it instead. If you get stuff in your `git status` about changes in a submodule within a larger project try the update command.
Heather Ratcliffe
02 May 2018 11:28
| ![]() Tags: Code Git Programming
| Comments (0)
| Report a problem
Tags: Code Git Programming
| Comments (0)
| Report a problem
April 20, 2018
Proper Planning and Preparation
There is an old, supposedly military adage, which reads
Proper Planning and Preparation Prevents Piss Poor Performance.
This applies to many things, including software development projects. There is also a popular idea known as Hofstadter's Law:
It always takes longer than you expect, even when you take into account Hofstadter's Law.
This is an amusing idea, but is sometimes allowed to apply to real life, which rapidly spirals out of control. There are many reasons a software project keeps taking longer the more you work on it, most of which are best avoided. This post is a brief introduction to how to plan, how to work, and how to keep things on track.
Software for Research
RSE is Research Software Engineering, which can mean many things, but ultimately means we are in the business of writing software used for doing research. Similarly, researchers-who-write-code should be aiming to for the least work which gets them reliable, verifiable, useable code. Note that usable includes being fast enough, and reliable includes doing enough testing.
This makes planning and scheduling essential, to make sure work gets done in time to produce research outputs, but also means it should be lightweight, simple and flexible.
Why Plans Fail
No plan survives contact with the enemy
(A well known paraphrase of a quote by H. von Moltke). Just like Hofstadter's law, one can add the corollary 'even if you include that in the plan'. Knowing the challenges ahead of time lets you plan around them, which gives the vast chance of something from the plan surviving. The following are the commonest sorts of issues to consider.
Shooting in the Dark
It's quite common to start a project not knowing exactly how to do it. This is fine, but has to be allowed for in the plan. For instance, allowing time to write a small test problem using a new library/tool before jumping into the main project, or allowing time at the end to rewrite/refactor (see below). Do not fall victim to the sunk costs fallacy and continue something unpromising just because you have already invested time and effort into it.
Scope Creep
Scope creep is probably the biggest problem many people face with research code. What starts as a simple script turns into a complex behemoth, and never seems to end. A vital part of planning, particularly if you are shooting in the dark, is to decide exactly what the code must do, and once that goal is reached, to stop. This is the perfect point to rejig things, debug well, document, optimise etc, before making a new plan to add all the things you now know you need. Endless rolling feature addition is risky.
Debug Deluge
It isn't uncommon to see a programmer writing pages of code before ever testing if it runs, or even compiles. This goes away with experience, but is often replaced by a related issue, of writing a bunch of stuff and then finding out that it doesn't quite work and has created a debugging nightmare. A better approach is to work in chunks, making each bit work, testing it, and only then integrating it into the whole. This way there's no deluge of debugging to be done, which can take a very long time; only small pieces at a time which are easier to plan for. This is related to the programming style called Test Driven Development (see below).
Premature Optimisation...
...is the root of all evil (Donald Knuth). Until your code works, there is nothing to optimise, as you'd just be doing the wrong thing faster. However, it is important to consider what the code needs to do in the end, and design and plan something that will be fast and efficient enough.
Refactor or Rewrite
Refactoring is rewriting pieces of a code so that the blocks (usually functions) give the same answers but are simpler, faster, more maintainable etc. Rewriting covers more substantial changes, such as changing core data structures or moving from hard-coded input values to a configuration file etc.
Getting Agile
If you have seen any of the Indiana Jones films, you may notice he applies something very like this. Rather than crafting a complex plan and trying to implement it in the face of changing circumstances, he adapts to things as they happen and is never more than a step, or a few steps ahead. This is basically the idea behind the 'Agile Methodology' of software development.
Since clients (or in our case, a research problem) change what they need over time, the idea is to plan only a few weeks ahead, adapting to changing needs as they arise. This is great for commercial development, which is all about happy customers, but does have a few pathologies for research software if done strictly. The main concerns are stopping yourself letting your scope creep out of control, and getting good enough time estimates to be sure you can complete a project, and that it will benefit you.
It's well worth reading a few articles about Agile to see what it's all about, and taking any bits you feel are useful for your own development.
Test Driven Developement (Lite)
'Test-driven-development' (TDD) means writing tests first, and considering a piece of code complete once it passes them, at which point it is done and work should stop. This has plenty of advantages, in particular that you avoid the pitfall of writing the test already knowing how the code works, which often leads to writing a test you know will pass.
The over-literal genie crops up all over the place and something very similar happens when you give clever people a set of rules. For a lot of scientific code, the natural test set is a handful of analytically soluble problems, for which exact answers are known. Using these as the test suite, the obvious, and strictly correct, TDD approach is just to hard-code their solutions. Every test passes, and the code is complete and usually completely useless too.
Rather than strict Test Driven Development, we'd recommend using writing tests for functions before or just after you finish them, making sure they work for all the parameter ranges etc that you need especially things like negative numbers, and then keeping the tests for when or if you change those functions. Rather than running everything every time you make changes you can just run the relevant tests and satisfy yourself that nothing is broken and then focus on integrating pieces together and making sure they all work in combination.
Planning for a Project
Everybody has their own way of planning, and really the only important thing is to do something so that you can estimate how long something will take and keep yourself honest along the way. For small things you only need to take an educated guess how many hours or weeks something will require. For more complex projects you may want to consider some kind of itemised planning process.
This file project_estimatorwexample.pdf is an example of such a planning worksheet, including an example based on my last project. This sheet tries to calculate a time requirement based on some common factors in research code. The multipliers and scalings are only a guess, and the last section adds an arbitrary buffer factor, but this would hopefully provide a starting point for making formal time estimates.
Last Word
This is quite an eclectic post, running through a few bits of useful knowledge that often get left out of programing introductions. The core point is simply
If you fail to plan, you are planning to fail!
Make a plan, stick to it as far as possible, but don't plan so far ahead that you're constantly wasting time re-forming your plans instead of getting work done!
Heather Ratcliffe
20 Apr 2018 13:09
| ![]() Tags: Code Programming
| Comments (0)
| Report a problem
Tags: Code Programming
| Comments (0)
| Report a problem
April 04, 2018
Valgrind and Extended Precision
Valgrind is an invaluable tool for checking for memory errors in compiled code. Briefly, it runs your code inside its own runtime which includes checked versions of system functions like malloc, so can detect undefined variables, memory leaks and much more. Using this on one of my C++ codes, I found something rather odd. When I ran normally, I had no problems, but inside valgrind I got unexpected NaN results. The actual code, in Minimum Working Example form was
#include <boost/math/special_functions.hpp>
#include <iostream>
int main(){
double arg = -5.58377179584844451;
std::cout<<"Bessel call "<<boost::math::cyl_bessel_j(5+1, (float) arg)<<'\n';
std::cout<<"Bessel call with double "<<boost::math::cyl_bessel_j(5+1, arg)<<'\n';
}
Running normally, I got the expected answer of 0.196642 for both calls. Run inside valgrind, the float version was unchanged, but the double version became NaN! This was very strange. Until I constructed the example above, I assumed the bug was elsewhere within my code, and not with the Bessel functions themselves.
After a lot of head-scratching and searching, I found a link to the valgrind manualand the answer:
Precision: There is no support for 80 bit arithmetic. Internally, Valgrind represents all such "long double" numbers in 64 bits, and so there may be some differences in results. Whether or not this is critical remains to be seen.
After a bit more searching and then checking of DBL_MIN and LDBL_MIN from limits.h I had an answer:
#include <limits>
#include <iostream>
int main(){
std::cout<<__LDBL_MIN__<<'\n';
std::cout<<__DBL_MIN__<<'\n';
std::cout<<"Minimum value is "<<std::numeric_limits<long double>::min()<<'\n';
}
Normally one gets a result like:
3.3621e-4932 2.22507e-308 Minimum value is 3.3621e-4932
In valgrind once again:
0 2.22507e-308 Minimum value is 0
So the limited 80-bit support referred to was, on my platform at least, breaking __LDBL_MIN__ which should be the smallest representable non zero value. Since the real problem is happening off inside boost::bessel somewhere, there's no simple fix. Most likely, the problem is that boost uses __LDBL_MIN__ to soften a division, preventing a divide by zero which later results in a NaN. The easier workaround requires that you detect running inside valgrind and adjust calculation. This is easy using the supplied macro:
#include "valgrind.h"
#ifdef RUNNING_ON_VALGRIND
if(RUNNING_ON_VALGRIND){
//Alternative path here
}
#endif
Note valgrind.h is specially licensed, differently to the rest of Valgrind, so that including it in your code does not require you open-source your code. Inside the special path, I used a float version of the bessel call, since inside valgrind I am interested in general output, but don't need the full precision of a double.
Another alternative overrides __LDBL_MIN__ before including the boost header. I chose to set it equal to __DBL_MIN__ Note this only works with header-only libraries and is a bit risky. The code becomes something like:
#undef __LDBL_MIN__
#define __LDBL_MIN__ __DBL_MIN__
#include <boost/math/special_functions.hpp>
#include <limits>
#include <iostream>
int main(){
std::cout<<__LDBL_MIN__<<'\n';
std::cout<<__DBL_MIN__<<'\n';
std::cout<<"Minimum value is "<<std::numeric_limits<long double>::min()<<'\n';
double arg = -5.58377179584844451;
std::cout<<"Bessel call with double "<<boost::math::cyl_bessel_j(5+1, arg)<<'\n';
}
Sometimes, the bug really is in the compiler or tool!
Heather Ratcliffe
04 Apr 2018 13:04
| ![]() Tags: Bugs Code Cpp Precision Valgrind
| Comments (0)
| Report a problem
Tags: Bugs Code Cpp Precision Valgrind
| Comments (0)
| Report a problem
 Loading…
Loading…

