All 10 entries tagged Programming
View all 127 entries tagged Programming on Warwick Blogs | View entries tagged Programming at Technorati | There are no images tagged Programming on this blog
September 19, 2018
Scheduling and processor affinity
We're taking a brief break from data structures to talk about something a bit different : scheduling and processor affinity. This is dealing with a problem that a user or developer doesn't usually think about, but is crucial to the performance of modern computers. Describing the problem is quite simple : if you have a computer that is doing multiple tasks what order should they happen in and what processor (if you have more than one) should take on each task? Working this out is the preserve of the very core part of the operating system (OS), generalled called the kernel (after the part of the nut). While the term is most familiar from the Linux/Unix world (technically Linux is the name for just the kernel and not the rest of the OS), macOS has the Mach microkernel at it's core and ntoskrnl.exe (the Windows New Technology Kernel! It was new in the mid 90s at least) is at the core of modern versions of Windows.
The simplest solution is for the kernel to just create a queue of programs that have to be done and then run them one after the other, with each new program being handed to the next free processor and programs running until they are finished. This is typically called First In, First Out scheduling (FIFO, which is a very common acronym in computing. Do not confuse this with GIGO (garbage in, garbage out) which is also a very common acronym in computing). FIFO scheduling works very well for computers that are working on lists of tasks having equal priority. So batch processing of data for example works very well with FIFO scheduling. But you can immediately see that it won't work well for all computers that humans actually work with interactively. If all of your processors are working on long, slow processes then your computer would stop working completely and you wouldn't even be able to stop the processes because the computer wouldn't be processing your keyboard or mouse input.
Normal computers tend to work using a system of preemptive scheduling. This works by taking a program and letting it run for a while on a processor and then saving its state, stopping it and then giving the processor another program to run on that processor for a while until stopping it etc. etc. Eventually you get back to a process that has been running before and you restore it's state and start it running again. Because the state of the program is stored completely it is entirely unaware that this has happened to it, so it just runs on regardless. (as a historical note, this is called preemptive scheduling because the OS kernel preempts the programs running on it. It basically says "you're done, get out of the way" and lets other programs run. Older systems used cooperative scheduling where a program would have code in it where it said to the kernel "I'm ready to be switched away from". This worked fine until a badly behaved program didn't reach this point whereupon every other program on the computer stopped working.)
There are disadvantages to preemptive scheduling. The saving and restoring of the state of programs is generally called "context switching" and it does take time for this to happen. (FIFO schedulers don't have this problem because programs run until they complete, but even now you can't really use FIFO schedulers because there tend to be dozens of programs running on a computer at once and some of the effectively nevercomplete until the computer shuts down). If you only have one processor then context switching is the inevitable price of allowing multiple programs to run at once, but if you have two processors and two programs then they can happily run alongside each other so long as they are each running on their own processor.
But what if you have four programs and two processors? As you'd guess, in general you'll put two programs on each processor. But what happens if the processors aren't running through their jobs at quite the same rate? This can happen because real schedulers are rather more complex than I suggested here. In that case, you can come to a situation where the program that was running on processor 1 reaches the point where it should run again but processor 1 is still busy. Should it then be run on processor 2? The answer, is "maybe". Sometimes programs benefit a lot from data being held in the fast CPU cache memory and if it now runs on a different processor then that benefit is lost. Under that circumstance it would be better to keep that program running on the same processor even if it has to wait a bit longer until it runs again.
All common operating systems let you do this and it is called "processor" affinity. You tell the kernel which processor (or processors) you want a given program to run on and it guarantees that it will respect that rather than giving that program to the next available processor.
I've glossed over a lot of things about scheduling here (in particular Intel's Hyperthreading technology is a nightmare for scheduling because it creates "virtual" processors to try and take advantage of the fact that most programs don't use all of the parts of a processor at once. The problem is that these virtual processors don't behave the same way as real processors so the scheduler has to be much more careful about what programs it should run on them.), but this is a decent overview of how scheduling and process affinity works on modern computers and generally it works quite well. General purpose programs don't set CPU affinity and just run as quickly as possible when a processor is free, and programs that do heavy numerical computation set CPU affinity to try and maximise cache performance. But there are interesting cases where it can fail.
Recently we had an interesting discovery using the OpenMPI parallel programming library. This is a distributed programming library intended to write programs to run on large "cluster" computers that consist of lots of single compute nodes connected by a network. But it does also work to run programs on a single computer. We were testing a computer with 16 cores and found that running a single 16 processor job was about 16 times faster than the same problem on a single core. When we tried the same problem with 4 simultaneous 4 processor jobs things were very different. The 4 processor jobs were all slower than they were when running on a single core. After a couple of hours we found out why: OpenMPI sets processor affinity for all of the programs that it runs, but it always sets them for the lowest numbered processors. So running a 16 core job ran them on cores 0 to 15, but running 4 sets of 4 core jobs ran them allon processors 0 to 3, so they all basically got a quarter of 4 cores. Add in some overhead from context switching and you get that it's slower than running on a single core. One quick parameter to the library to tell it not to use processor affinity and we were back to where we expected to be, but the lesson to take away is that you can get far to used to things like schedulers just working. If you're finding that things are running slower than you expected, check whether or not there's something odd going on with how your processors are being used.
 Christopher Brady
19 Sep 2018 17:16
|
Christopher Brady
19 Sep 2018 17:16
| ![]() Tags: Programming
|
Tags: Programming
|  Comments (0)
|
Comments (0)
|  Report a problem
Report a problem
 Please wait - comments are loading
Please wait - comments are loading
September 05, 2018
Data structures 2 – Arrays Part 2
Part 2 of arrays is about dynamic (run time) sized arrays. That is arrays where you don't know how large they're going to be until the code is running. First, I'll go through it in Fortran because it is really easy in Fortran, and powerful array operations are one of the major advantages of Fortran.
Dynamic arrays in Fortran are generally called ALLOCATABLE arrays (there are also POINTER arrays, but they are generally harder to use for only fairly specific benefits), and you declare them pretty much the same way that you declare any array in Fortran
INTEGER, DIMENSION(:), ALLOCATABLE :: myarray
You then allocate it using
ALLOCATE(myarray(0:100))
First, note that the DIMENSION(:) syntax in the variable declaration is the same as when you're passing an array to a function where you don't know how big the array is. This is the general way of telling Fortran "I don't know what size this is until runtime" (there are a few features where it's * instead for things like the length of strings, but in general it's :). Also note that I have explicitly allocated the array bounds, with the array running from 0 to 100 inclusive. If I'd just used
ALLOCATE(myarray(100))
then the array would have run from 1 to 100 inclusive. In Fortran you can have any upper and lower bounds for arrays that you want which is sometimes useful. You do have to be careful though because unless you are careful when you pass arrays into functions these bound markers are ignored inside the function and the array just runs from 1:n.
Moving to multidimensional arrays in Fortran is easy.
INTEGER, DIMENSION(:,:), ALLOCATABLE :: myarray
ALLOCATE(myarray(0:100, -1:101))
myarray(10,10) = 1
will create a 2D column major array with the array bounds that I specified in my allocate statement. Job done. Fortran ALLOCATABLE arrays also have the nice property that they are automatically deallocated when they go out of scope so it's much harder to have memory leaks with Fortran ALLOCATABLE arrays (you don't have this guarantee with POINTER arrays because this doesn't make use of reference counting and garbage collection. It relies on the fact that there can only be a single reference to a Fortran allocatable.). If you want more control over when memory is returned to you then you can also manually DEALLOCATE the array
DEALLOCATE(myarray)
Before I start on the C section, I should note one thing: C99 and later standards do define variable length arrays (usually referred to by the acronym VLA). They aren't really very common in scientific code and they have all sorts of oddities about how you use pointers to them and where you can and can't use them (you can't have them in structs for example). Given their general rarity and strangeness (and the fact that they aren't valid in C++ before C++14) I'm not going to talk any more about them, but they do exist and you might want to look them up if you're writing a new code in C. 1D run time arrays in C are traditionally created using the "malloc" memory allocation function. You tell malloc how many bytes of memory you want and it creates a chunk of memory that long and hands you a pointer to it. The syntax is easy enough
#include <stdlib.h>
int main(int argc, char **argv){
int * myarray;
myarray = malloc(sizeof(int) * 100);
myarray[0] = 10;
free(myarray);
}
Note the use of the "sizeof" operator to find out how many bytes are needed to store an integer. If you want to write code that works on multiple machines you'll have to use this because integers are not always the same size. In most senses you can consider a pointer and a 1D array to be very similar in C. When you use the square bracket operator you get the same element of your array in both cases, and in fact the layout of the memory behind the scenes is conceptually similar (although if you want to be precise a static array will generally be allocated on the stack, while malloc gives you memory from the heap). Also, note that I have used the function "free" to delete the memory when I am finished. If I don't do this then there will be a memory leak. C explicitly does not keep track of memory at all. Sadly it gets rather harder in multiple dimensions.
malloc always gives you a 1D strip of memory, and there is no equivalent function to give you a multidimensional array in standard C. My preferred solution is just to allocate a 1D array and then use an indexing function to access the element that you want. For example
#include <stdlib.h>
int main(int argc, char **argv){
int * myarray;
int nx, ny; /*Size of array to be filled somehow*/
int ix, iy; /*index of element to access to be filled somehow*/
myarray = malloc(sizeof(int) * nx * ny);
myarray[ix*ny + iy] = 10;
free(myarray);}
This will work perfectly and will give pretty good performance. Usually you'd write some kind of helper function or macro rather than having ix*ny+iy all over your code, but this shows the general technique. You do have to be careful writing your index function though because [ix*ny + iy] gives you a row major array and [iy*nx + ix] gives you column major. This can be useful but you need to be sure what you're doing. The other problem with this is that you can't just access your array as if it was a compile time multidimensional array. If you try to access this using myarray[ix][iy] you will get a compile error. This is because behind the scenes the [] operator dereferences your pointer with an offset (you can replace myarray[ix] with *(myarray+ix) if you like pointer arithmetic). Because of this when the first square bracket has happened you are just left with an integer, so the second square bracket operator is an invalid operation. So can you keep the multidimensional access? Yes, but there are always downsides.
#include <stdlib.h>
int main(int argc, char **argv){
int **myarray;
int nx, ny; /*Size of array to be filled somehow*/
int ix, iy; /*index of element to access to be filled somehow*/
int ind; /*Loop index*/
myarray = malloc(sizeof(int*) * nx);
for (ind = 0; ind<nx;++ind) myarray[ind] = malloc(sizeof(int) * ny);
myarray[ix][iy] = 10;
for (ind = 0; ind<nx;++ind) free(myarray[ind]);
free(myarray);}
This works by making myarray a pointer to a pointer to an int (int **myarray). You then allocate the outer pointer to be an array of nx pointers to int (note that my first sizeof is now sizeof(int*), not sizeof(int)!). You then go through all of these pointers to integers and allocate those pointers to themselves be ny element long arrays of integers (note that the second sizeof is sizeof(int)). This will work as expected, and you can now index your array with square bracket operators as normal, so what's the problem. The problem is that malloc doesn't give any guarantees about where the memory that you get back from it is located. In this simple test case the memory that you get will probably be layed out in a contiguous block, but in general this won't be true. By splitting your memory allocation up like this you are potentially creating a memory prefetch problem much like the one that you get by accessing an array in the wrong order, with similar effects on performance. There is a fringe benefit for this type of array : because the rows are allocated separately they don't have to be the same length as each other. It's tricky to make use of this property (because you have to keep track of how long each row is yourself) it can be very powerful for certain types of problem. On a related note you will often find that multidimensional arrays in C++ are created using std::vector<std::vector<int>> types. This in general has the same type of problem with memory not being contiguous, as you can clearly see from the fact that you can push back into each vector individually.
The final solution is to create a 1 dimensional chunk of memory and then rather than using an indexer function use a separate list of pointers to the start of the row. There are lots of ways of doing this, and this example isn't a terribly clever one but it does work
#include <stdlib.h>
int main(int argc, char **argv){
int nx = 10, ny=10;
int ind;
int **myarray;
int *buffer;
myarray = malloc(sizeof(int*) * nx);
buffer = malloc(sizeof(int) * nx * ny);
for (ind = 0; ind< nx; ++ind) myarray[ind] = &buffer[ind * ny];
myarray[5][5]=54;
free(buffer);
free(myarray);}
Christopher Brady
05 Sep 2018 17:18
| ![]() Tags: Code Programming
| Comments (0)
| Report a problem
Tags: Code Programming
| Comments (0)
| Report a problem
August 08, 2018
Data structures 1 – Bitmasks
This month we're going to start an occasional series on data structures. Data structures are one of the core foundations of computer science, but are often underappreciated by general academic programmers. A large part of this is simply that data structures are usually chosen early in development of a code and are only rarely changed as the code evolves. Since most people don't start a code themselves, but simply work with an existing one, you only need to know how to work with a given data structure rather than why it was chosen or why it's a good choice. To try and remedy this we are going to create a few blog posts on common data structures, why they are chosen and how to implement them.
The first one is definitely one from the archives, being a trick that was more useful when computers only had a few kB of memory available to them, but is still used in modern codes because of it's simplicity. This month, we're going to be talking about bitmasks.
Bitmasks
Bitmasks are solutions to the problem of you having a large number of simple logical flags that you want to keep track of and keep together. The common uses are things like status flags (what state is this object in), capability flags (what can this object do) and error flags (which errors have occured). The answer seems obvious:
LOGICAL, DIMENSION(N) :: flags !Fortran
std::vector<bool> flags; // C++
char[N] flags; /*C*/
In fact, none of these are guaranteed to use as little memory as is needed to store your data.
In fact, since all that you are storing is a single true/false state all that you need is a single bit for each state, so you can store 8 states in a byte. So how do you do it? Unsurprisingly, you need to use bitwise Boolean logic. In particular you will probably find uses for bitwise OR, bitwise AND and bitwise XOR. The syntax for these varies between languages but almost every language has them
| C/C++/Python | Fortran (95 or later) | |
| Bitwise OR | A | B | IOR(A, B) |
| Bitwise AND | A & B | IAND(A, B) |
| Bitwise XOR | A ^ B | IEOR(A, B) |
Bitwise operators are exactly the same as logical operators but they operates on each bit individually. So you go through each bit in the two values and operate as if each was a logical flag. As an example, imagine 15 OR 24
| Bit/Number | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
| 15 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| 24 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 |
| Result = 31 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 |
Every bit that was set in either of the two sources is set in the result. To make practical use of this, define named flags for each bit that you want to use. In this example I'm going to assume that I want my bitmask to represent error states based off a real code that I've worked with.
/*NOTE these values must be powers of two since they correspond to individual bits. Bitmasks don't work
for other values*/
char c_err_none = 0; //No error state is all bits zero
char c_err_unparsable_value = 1; //Value that can't be converted to integer
char c_err_bad_value = 2; //Value can be converted to integer, but integer is not valid in context
char c_err_missing_feature = 4; //Code has not been compiled with needed feature
char c_err_terminate = 8; //Error is fatal. Code should terminate
You can do the same in Fortran or Python, although Fortran still doesn't have a portable "char" equivalent so you'll have to use integers. Once you have your list of constants, you can write code to use them for error values. For example
/*Set errcode to c_err_none to start*/
char errcode = c_err_none;
if (value == c_feature_tracking) {
if (!tracking_enabled){
errcode = errcode | c_err_missing_feature; /*Feature is missing so or with c_err_missing_feature flag*/
errcode = errcode | c_err_terminate; /*Code should not continue to run so or with c_err_terminate*/
} else { ... }
}
This code tests for value being a value that the code hasn't been compiled with and sets two error state bits by combining the errcode variable with the constants c_err_missing_feature and c_err_terminate. This sets the correct two bits and errcode now has the error state stored safely in it. But how do you read it back? By using AND. If I want to test for a state, I simply AND the errcode variable with that state. To demonstrate
| Bit/Number | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
| errcode | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| c_err_terminate | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| Result = 8 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
Since the value c_err_terminate has been set, the result is just the value of the bit corresponding to c_err_terminate. But what if I test a bit that isn't set?
| Bit/Number | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
| errcode | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| c_err_bad_value | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| Result = 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
The result of the AND operation is just zero. So to test for a bit being set, simply AND your error variable with the flag being tested and test if the result is zero or not. In languages like C or C++ where conditionals can just test for a value being zero or not, this is as simple as
if (errcode & c_err_terminate) { ... }
But in Fortran where the IF statement needs to take a logical, you have to explicitly test against zero
IF (IAND(errcode, c_err_terminate) /= 0)
The other common task with arrays of logicals is to flip the state of a bit. So if it is set, unset it and if it's unset, set it. You do this using the XOR operator. XOR is a little less common than AND or OR, so I'll explain it briefly.
XOR is exclusive OR and it has this truth table
| 0 | 1 | |
| 0 | 0 | 1 |
| 1 | 1 | 0 |
So if either, BUT NOT BOTHof the inputs is 1 then the output is 1. Otherwise the output is zero. You can see what that does to a bitmask simply enough by considering if I want to flip the state of the c_err_terminate bit in my previous bitmask
| Bit/Number | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
| errcode = 12 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 |
| c_err_terminate | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| Result = 4 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
You can see immediately that by performing the same operation again I'll just set the c_err_terminate bit back.
So by combining the values with XOR I simply flip the state of the bit that I am interested in while leaving everything else alone. In code this is very simple
errcode = IEOR(errcode, c_err_terminate) !Fortran
errcode = errcode ^ c_err_terminate /* C/ C++ or Python */
Christopher Brady
08 Aug 2018 16:42
| ![]() Tags: Programming
| Comments (0)
| Report a problem
Tags: Programming
| Comments (0)
| Report a problem
July 11, 2018
Maths in Code
Programming Equations
Short post this week, with a simple theme: how should you translate equations into code?
Self Documenting Code
Self-documenting code (aka self-describing code) is code that documents itself, rather like the term 'self-documenting code' already tells you what it means. The idea is to choose function names, variable names and types, and (in relevant languages) Class or Object hierarchies so that they demonstrate what they do. This can mean a lot of things, and tends to mean slightly different things to different people. In general, especially in cases of ambiguity, one aims for the "principle of least surprise" - what is the least unexpected meaning of something with this name? For instance, old fashioned C programmers, might consider "i" to be a perfectly self-documenting loop variable, as the usage is very familiar.
This leads us nicely into the spirit of self-documentation. Programming is hard. Choosing sensible names and structures reduces the effort needed to keep track of what things are, as well as everything else in your program. This means that the names you choose should help you, and whoever reads or uses your code, work out what things mean. Imagine coming back to your code after weeks or months not working on it. Can you read it through and guess, correctly, what things mean? If not, consider reworking your namings or structure.
Names shouldn't just repeat information already available though, as that wastes space which could be better used. For example, a boolean or Logical variable already tells you that this is probably some sort of flag, controlling whether or not something should happen or has happened. "write_to_file" is a useful name. "flag" is not. "is_open" is a useful name for a flag associated with a file, "open_flag" is rather less so.
On this note, there is a common naming scheme which uses so-called Hungarian Warts, where some sort of 'type' information is prepended using a few (< 3) letters. Originally these were used to add 'extra' information, such as 'us' for 'unsafe string', which can be very useful. In languages like Python, where definitions don't specify type info, even just tages like 's' for string can be useful, as long as you make sure this is actually true!
Don't go mad with descriptions though. Supposedly the average person can keep 7 things in mind at once so you definitely don't want to occupy all that space with your variable names. 2 or 3 pieces is about the limit for most names, so try and use things like "input_file" not "file_to_read_data_from" and avoid linking words as far as practical. Keep names short and sweet, to save typing and brain-space.
By the way, if you use an IDE to program, you might feel that none of this matters, but while it will fill in the names for you, it really doesn't solve everything. You still need to keep track of which variable you want and select the correct one in ambiguous cases, and keep track in your head of what is what. The self-documenting ideal means that when your IDE gives you a list of 5 similar looking variables, you barely have to think to select the one you need in context.
Self Documenting Equations
Take a nice simple equation, ax^2 + bx + c = 0 and imagine programming something to solve it. If you took the self-documenting advice at face value, you might convert "x" into "polynomial_variable", and "a, b, c" into "coefficient_of_square_term", "coefficient_of_linear_term" and "coefficient_of_constant_term". That leaves the quadratic equation looking pretty complicated, as
polynomial_variable = (- coefficient_of_linear_term +|- sqrt( coefficient_of_linear_term^2 - 4 * coefficient_of_square_term * coefficient_of_constant_term) )/ (2 * coefficient_of_square_term)
instead of the far more familiar
x = (- b +|- sqrt( b^2 - 4 * a * c)) /(2 * a)
Similarly, if you program equations from a paper, it can be much, much easier to use variable names that match the paper, especially when trying to verify them. Sometimes it is even a good idea to mimic the paper's equation format, at least until things are working. More on that in the next section.
Optimising Equations from Papers
So what about rearranging equations for optimisation purposes? If you ask ten different people, you'll get ten different answers, but in my opinion the following are the keys:
- Only simplify once the code works. Don't bother collecting, hoisting or other tweaks until you need to.
- Keep names generally the same as the paper, but ideally remove ambiguity, so don't use 'a' as well as 'A'. Consider 'a' and 'bigA' for more distinction. Absolutely avoid ambiguities like 'l' and '1'.
- When you do change to rearranged equations, consider leaving the original code present in a comment. This is one of the few places where commented code is a good thing.
- When you combine or collect terms, start by just combining their names or the functions use, so use 'A_squared', 'sin_theta' or 'A_over_B'
- Include a link to the paper or source you used in the code, so that your variable names remain useful. Somebody with a source that uses different namings will find this style really tricky. If you can, consider including a snippet in your docs detailling the original equations and what rearrangements you did.
Find your style, stick to it, and optimise only as much as necessary to get the performance you need!
Mathematica for Complicated Expressions
If your equations need substantial rearranging or simplifying, you might turn to a tool like Mathematica to do this for you, but did you know that it can even write C or Fortran code directly?
https://reference.wolfram.com/language/tutorial/GeneratingCAndFortranExpressions.html
You can save a lot of typing, and avoid some really easy mistakes by taking advantage of this. Don't forget FullSimplify and to apply suitable restrictions on variables to get a nicer expression before doing this though.
Heather Ratcliffe
11 Jul 2018 11:20
| ![]() Tags: Code Mathematica Programming
| Comments (0)
| Report a problem
Tags: Code Mathematica Programming
| Comments (0)
| Report a problem
June 27, 2018
More randomness
Dealing with randomness and random samples of distributions is a huge area, but we're going to finish these posts by considering one last big thing that we haven't touched on at all : random distributions in multiple variables. These look at the question of what happens if you have a set of related variables where the probability of one having a given value of one variable affects the probability of having a given value in another variable. You do have to be a little bit careful though because not all probability functions in more than one variable have this property. A classical example from physics of one that doesn't is the distribution of velocities of particles in a gas.
Particles in a gas are free to move in any direction that they want to, so they have three velocity components since the universe is has 3 spatial dimensions (at least to a good enough approximation for this problem). In fact, the distribution of velocities is given by the Maxwell-Boltzmann distribution, which is basically the Gaussian or Normal distribution that we saw earlier. Mathematically, this looks like
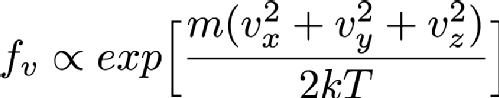
Where Vx, Vy and Vz are the x, y and z components of the particle's velocity, m is the mass of the particle, k is a constant called Boltzmann's constant and T is the temperature in Kelvin (Which is the same as centigrade but offset so that 0C is 273.15K. 0K is "absolute zero" which doesn't exist in nature, so it's fine that this equation breaks at T=0). If you've not seen it before the alpha symbol rather than = means that I'm hiding a constant multiplier in the equation. Using the properties of exponentials we can rewrite this as
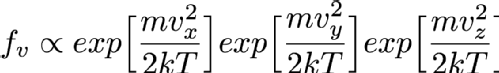
Imagine now that you have chosen Vx. That first exponential then just becomes a constant and can be absorbed into the constant that I'm hiding in that alpha symbol so the distribution of Vy and Vz aren't changed by selecting a Vx. That means that I can simply choose Vx, Vy and Vz independently and since they are all Normally distributed I can use the Box-Muller transform that I mentioned in the previous randomness post so I can sample it very fast. Always look at the mathematical description of your distribution to see if you can break it down like this into simpler forms (in more technical language this is termed "seperability" of the equations). It's always faster to sample on a smaller number of variables if at all possible.
But there are some distributions that really can't be separated like this, for example consider
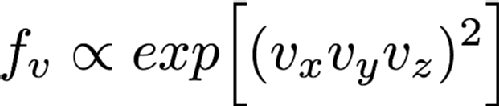
as far as I know this isn't a distribution that anyone is interested in, but it certainly could exist. You can't separate this into functions of Vx, Vy and Vz so you have to sample it in all three variables directly. In the previous post we mentioned inverse transform sampling. This involves forming the cumulative distribution function from the distribution function and sampling along that curve. You can in theory do this for multdimensional functions as well. You have to define a space-filling curve that covers the area of interest of the function and then integrate the PDF along this curve and then finally do inverse sampling along this curve. Doing inverse transform sampling analytically is already tricky and working along an arbitrary curve really doesn't help matters, so in general you have to do it numerically. This means that you have to define your function on a grid of some kind. The problem is that this grid has to have as many dimensions as you have variables, so in this case there's Vx, Vy and Vz so 3D. The more points you have in each dimension of your grid the better your numerical approximation is to the real distribution (you can do things like interpolating between grid points to make it better than the simplest implementation but this is still true overall). So if you want to have 1000 grid points in each direction for this 3D example you'd need between 4 and 8 GB of memory (depending on how you store your numbers, which also affects accuracy). That's possible on a pretty typical computer nowadays, but still a lot of memory. If you had an even harder 4 variable sampling function then this rises to 4-8 TB of memory which is the preserve of high end workstations costing tens of thousands of pounds, and by 6 variable sample functions it couldn't even be run on world leading supercomputers.
Fortunately there is an alternative called rejection sampling. It's much simpler to implement too, although the downside is that it can be much slower to run. You can comparatively easily change any distribution function so that it has a maximum value of 1. Simply find the maximum value in the range of interest of all variables (either analytically or numerically) and divide the distribution function by this value. What you have now is often called the "acceptance function". That is, if I randomly select a value for each variable (selecting this value as a uniform random number in some range of interest), what is the probability that I should accept this value and include it in my sample? This is why the you want a function that has a maximum value of 1 - you want there to be an "optimal" place where acceptance is guaranteed. Then you simply roll one more random value and if it is less than the random probability that you get from the acceptance function then you should take that value, add it to the list of values and continue. If it isn't then you just randomly select new values of all the variablesand keep going until the value is accepted. When you have accepted enough values for your purpose you just stop sampling.
This works beautifully and doesn't require that you allocate any arrays for your distribution function, so long as you can calculate it for any possible value of your variables. Since there's no array there's no problem with discretising the results and you get a nice smooth sample of your distributions function. The problem is in all of the times that you have to throw away sample points because they are rejected. This means that in general rejection sampling is quite slow. While there's no need to, pretend that you want to sample a Normal distribution in a single variable using rejection sampling. If you want to sample it out to one standard deviation from the mean then the average acceptance probability is 86% (ish), so it'll take about 16% longer to compute than it would to be able to simply specify the sample value directly (this isn't quite true because Box-Muller is quite complex and takes longer than a simple rejection sample, but I'm going to ignore this here). Unfortunately there are very few examples of problems where one standard deviation would be enough. In fact, a normal distribution to 1 standard deviation looks quite odd
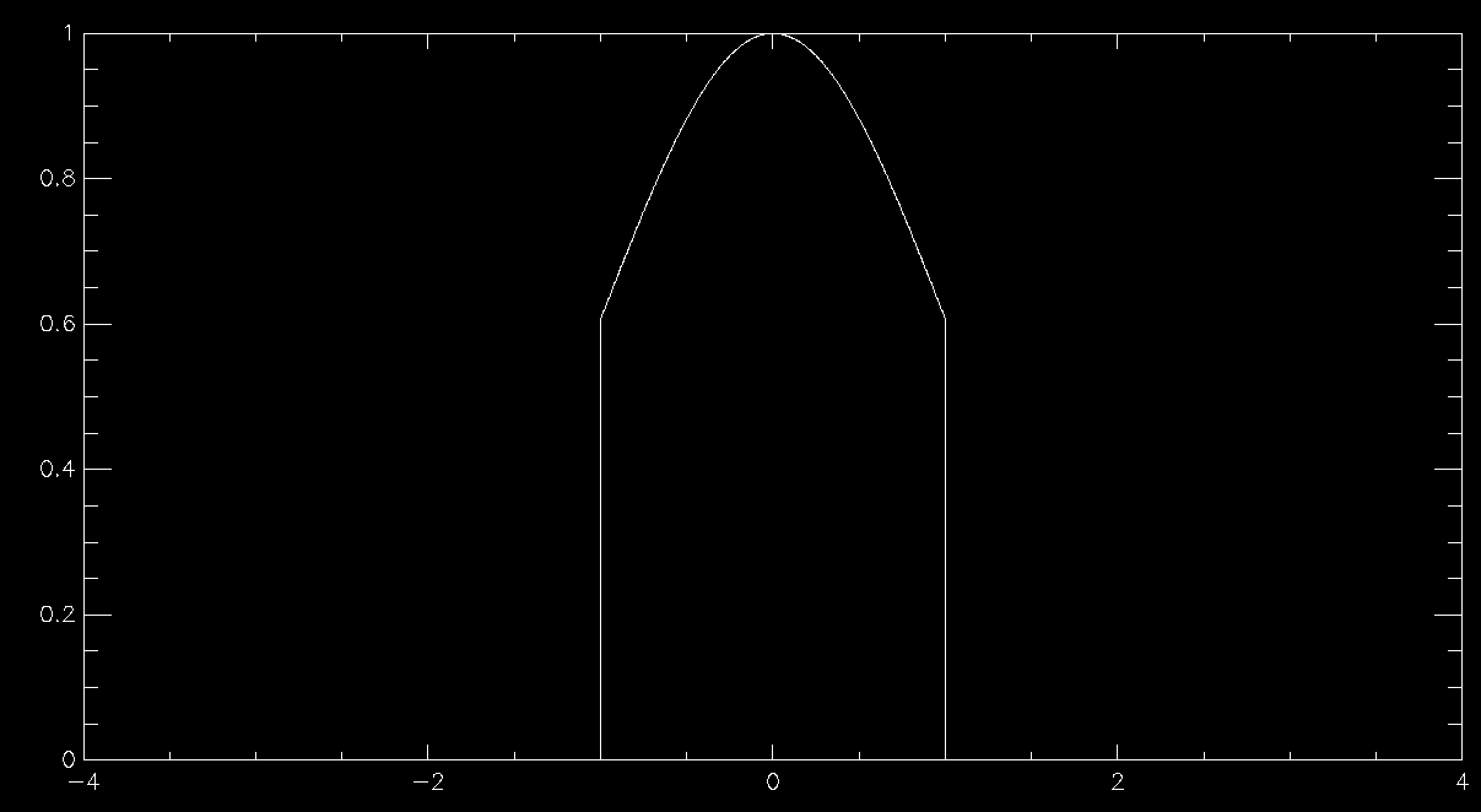
so you generally have to go further out. At 2 standard deviations you're now accepting about 60% of trials, so you're taking about 66% longer than simple sampling. At 3 standard deviations you're at 42% average acceptance and you're talking about taking 2.4 times longer than a simple sample. At 4 standard deviations you're now down at 31% average acceptance and you've having to do 3 trials for an average sample until you accept it. Unsurprisingly this takes about 3 times longer than simply being able to specify the value, but finally your Normal curve looks about right by eye. As you can see, rejection sampling really should be your last resort since Normal curves are about as benign as distribution functions get - most functions that you'd actually want to run acceptance sampling on have lower acceptance probabilities by the time that you are sampling everything that you want to.
There are more advanced algorithms that are better than rejection sampling (try looking at the Metropolis-Hastings algorithm if you want a place to start), so you're not completely out of luck if you've reached this point and rejection sampling is too slow, but things do start getting more complex from here on in.
Christopher Brady
27 Jun 2018 17:36
| ![]() Tags: Programming Randomness
| Comments (0)
| Report a problem
Tags: Programming Randomness
| Comments (0)
| Report a problem
May 31, 2018
More randomness and a bit of non–randomness
Normally distributed random numbers
The last blog post was about getting high quality, uniformly distributed random numbers. In this post, I'm going to address the question of what to do if you want to have non uniformly distributed random numbers, that is random numbers where some are more likely than others. One of the ways that we're going to be looking at this is by looking at Probability Distribution Functions(PDF). These graphs are very like histograms, but they instead say "I have a source of random data U. For the entire source U, what is the probability that any given value is in the range x to x + dx, where dx is a finite but usually small deviation from x". In practice, what you do is you split up the range of U into a series of bins of width "dx" and then just count the number of particles in each bin and divide by the total number of particles.
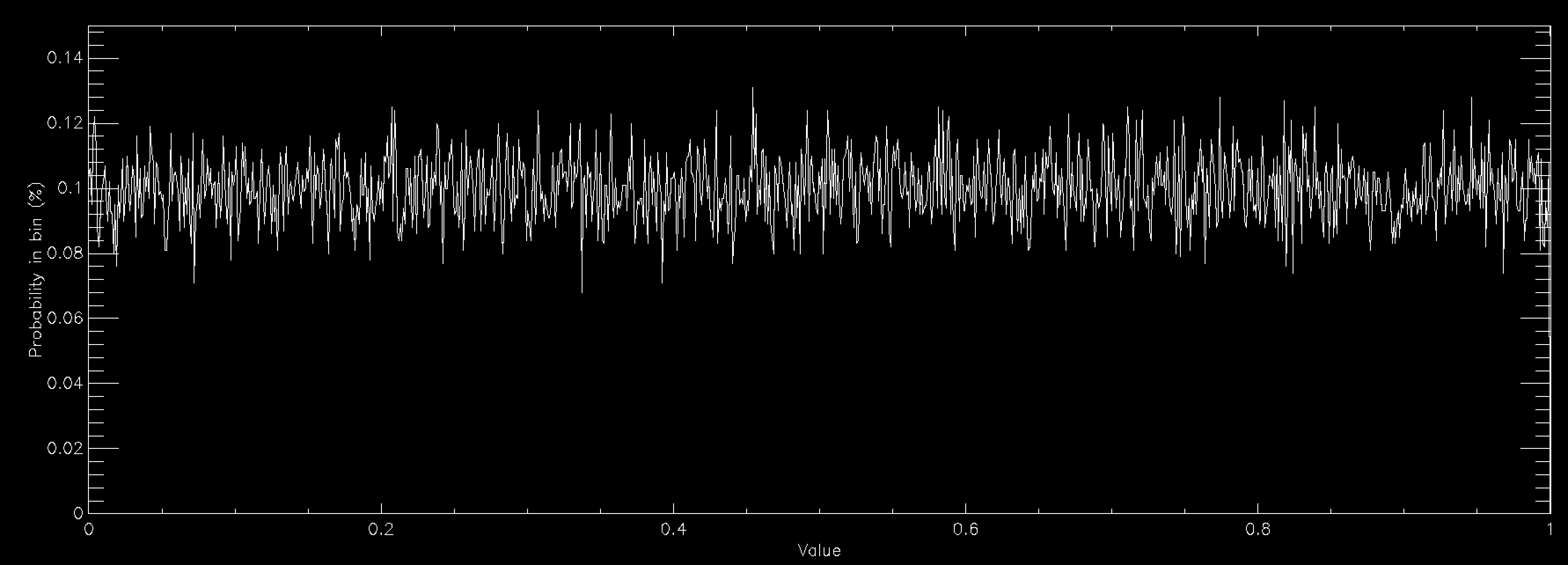
The above graph shows the probability distribution for a uniform random number when you have 1,000 bins between 0 and 1. This number of bins explains why the graph is showing a rough line centred around 0.1% probability. Since a uniform random number generator should produce values in all bins equally, you would expect (100/nbins)% (so 0.1% for 1,000 bins) to lie in each bin. The graph shows that the random number generator that I'm using is working reasonably well.
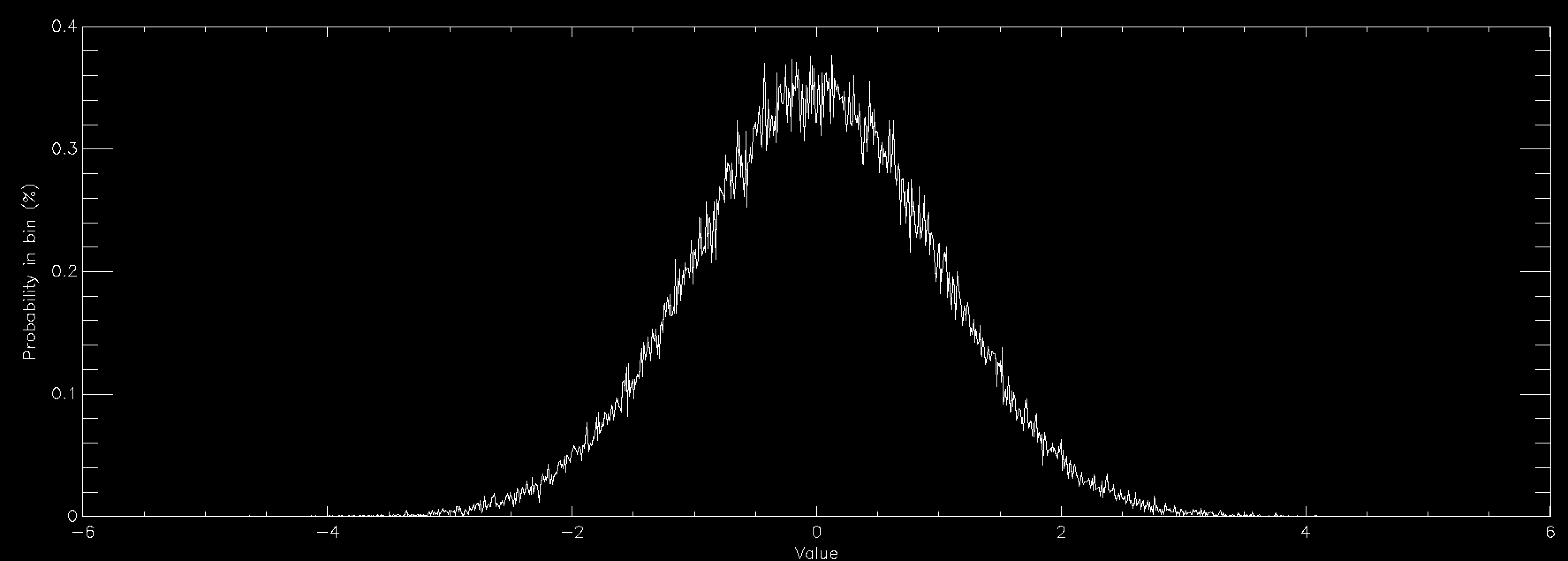
This graph shows the same thing for a normally distributed random number (also called Gaussian, or in some fields Maxwellian distributions and sometimes bell curves). It is strongly peaked at zero and extends out to ±6. Normal distributions are very important in many areas of study (see here for some examples), and is found in things as diverse as the distribution of speeds of particles in a gas to the distribution of heights of members of a sports club. As a consequence there is a lot of interest in generating normally distributed random numbers. This is often called "sampling" the distribution. The graphs above were created by getting random numbers and counting how many fell into each bin on the graph, but often you want to go the other way. You want to draw the graph and then get random numbers such that their distribution will match the graph.
Fortunately there's a very easy way of converting from a uniform random number generator to a normally distributed random number generator via an algorithm called the Box-Muller Transform. I'm not going to go into the maths of it which are detailed on the linked Wikipedia page, but if you want normally distributed random numbers the Box-Muller Transform is your friend (usually the specific variant called the Polar Box-Muller Transform). Lots of languages already have built in implementations of normally distributed random number generators, generally using that transform so it's worth looking for those first, especially in compiled languages like Python where the built in function will probably be much faster than yours. However, in languages like C or Fortran which don't have a built in one you probably want to find or write an implementation of the Box-Muller Transform if you need normally distributed random numbers.
Arbitrary distributions in one variable
Sometimes, however, you have a more complicated distribution function that you want to sample. Sometimes there are other transforms like Box-Muller, but quite often there aren't. At which point the most powerful tool you have is called Inverse Transform Sampling. This introduces a new idea the Cumulative Distribution Function (CDF). The CDF is very much like the PDF in many senses, but instead of saying "how much of U is between x and x+dx" it says "how much of U is between min(U) and x", hence the cumulative in the name. It is the accumulation of the probability of the value being at x or lower.
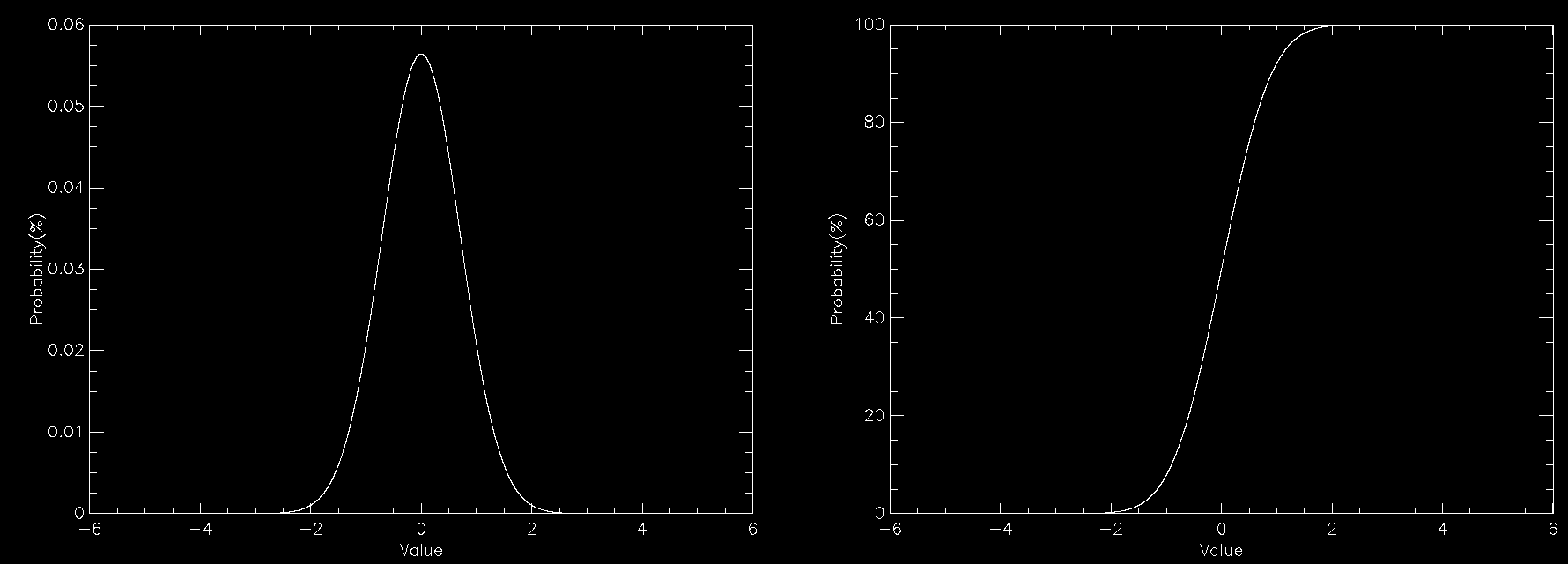
The graph this time compares the PDF (left) to the CDF (right) for a normally distributed number. The CDF has a value of 100% at the right because everything has to be less than the largest value. You can create the CDF in a number of ways, but on a computer a very common way is to define a grid of values (x(i), say) and calculate the PDF (PDF(i)) for each of them. This does mean discretising your distribution but that is often sufficient and you can often interpolate the result. The CDF is then simply defined by
CDF(i) = SUM(PDF(0:i))
where i is the index into a zero based array and is evaluated from 0 to n, where n is the number of elements in the array.
Once you have the CDF sampling it is surprisingly easy. You simply pick a uniform random number between 0 and 100 and then find out which value of i is the cell in which the CDF exceeds that value. You then have sampled the value x(i). You keep repeating this until you have sufficient values. If you then check the distribution of the values it will match the PDF that you specified. Effectively this divides the PDF into bins of equal area under the curve, and selects one bin at a time with equal probability. On the CDF graph, equal area bins correspond to a uniform division of the y axis.
The actual implementation of this can be a bit messier because while the easiest way of finding which cell of the CDF exceeds your random value is simply to start at i=0 and count up, the fastestway is to use binary bisection on the index. This works because the CDF is guaranteed to increase from left to right, so if you pick any point you know if the point that you want is to the left of that point if the value is smaller and to the right of the point if the value is larger. So you can keep dividing the space into sections until you have found the value that you want. But that is an implementation issue rather than a conceptual one.
Note also that if you can integrate the PDF to obtain a CDF, which you can then invert, you can do all of this analytically, but even simple PDFs like a Normal distribution don't have an invertible CDF.
Distributions in more than one variable
Distributions in more than one variable can be tricky. But if the function is separable, that is it can be written as two functions multiplied together, each of which is in a single variable (f(x, y) = g(x) * h(y)) each part can be sampled as above. For each complete sample you take one random sample of the function g, and one of h, and multiply them together.
Functions in more than one variable which don't break down like this are generally treated using a technique called accept-reject sampling, or some more sophisticated technique in tricky cases. More on this next time.
Christopher Brady
31 May 2018 11:55
| ![]() Tags: Code Programming Randomness
| Comments (0)
| Report a problem
Tags: Code Programming Randomness
| Comments (0)
| Report a problem
May 16, 2018
Randomness for computer programmers
Random numbers appear in almost everything that involves computers. The cryptographic algorithms that underpin almost all online commerce are based on random number generators, in academic use there is the entire field of Monte-Carlo simulations that use random numbers to generate and test configurations, and many computer games use random number generators to generate the rich behaviour that is observed without having a human have to program everything manually.
Despite their ubuquity though, random number generators (RNGs) are a little regarded element of computational techniques in most areas of academic use. Before I start, I want to stress something if you have been working with random numbers and haven't worried about the things that I'm talking about you are probably fine. You have to be careful with RNGs, but mostly any ones that you will encounter in the wild are good enough.
The first thing to do is to distinguish between true (or hardware) random number generators and psuedorandom number generators. True random number generators are hardware devices that convert random physical properties into random electrical signals and then convert them into random numbers. Even these are split into ones that use truly random sources (like the decay of radioactive nucleii) or chaotic sources (like atmospheric turbulence), but in general they produce sequences of random numbers that are non-repeating and unpredictable. You can read more about them here. True RNGs produce a signal that has maximum entropy for a signal of that length.
You might remember the concept of entropy from physics where it is a measure of disorder, so a system that is disordered (like a gas) has higher entropy than an ordered system (like a solid). Information entropy is very similar and represents a measure of surprise. If you have a signal that reads "1, 1, 1, 1, 1, 1, 1, 1" then being told that the next number is also "1" isn't much of a surprise, so that signal has low information entropy. If you have the signal "1, 1, 0, 1, 0, 1, 0, 0" then you'd be much harder put to guess what the next symbol is going to be so that signal has a much higher entropy. Information entropy is actually a fairly complex concept that can be measured in different ways (you can see more here) and explaining it in detail is well beyond the scope of a blog post, but you can easily see some of the complexity by an analogy. You could say that my second signal ("1, 1, 0, 1, 0, 1, 0, 0") was higher entropy than my first ("1, 1, 1, 1, 1, 1, 1, 1") because it has as many "1"s as "0"s, but what about the signal "1, 0, 1, 0, 1, 0, 1, 0"? On the one hand it has as many "1"s as "0"s, but on the other hand it can be represented by a very simple pattern and so you'd be less surprised if the next digit was "1" than if it was "0".
While true RNGs are extremely important in the real world, particularly in areas such as cryptography, most academic users don't use true random number generators, or use them only in combination with pseudorandom number generators (PRNGs).
PRNGs are algorithms that take a simple seed value and then operate on it to generate a sequence of numbers that has as many of the properties of a true RNG as possible. They are, by definition, not random. If you give them the same seed then they will always generate the same sequence, so they cannot contain any more entropy than is contained in the combination of the seed value and the algorithm. This means that they always perform worse than true RNGs. They do however work well enough for almost all scientific and statistical purposes if you choose a good one. Unless you are working on a system that requires Cryptographically Secure PseudoRandom Numbers (and if you are I'd hope that you aren't getting your information from a blog post!) then almost any modern PRNG is a good one. The only problem is that language standards don't update very fast, so some programming languages don't insist on a modern one in the standard library. Java uses an old algorithm called a Linear Congruential Generator, the C and Fortran standards don't require anything specific about the algorithm to be implemented and the popular GFortran compiler uses a very modern algorithm if you use the modern Fortran RANDOM_NUMBER interface and a very old one if you use the older RAND interface. The main thing to take away is that you should be very careful using language supplied random number generator. You cannot rely on the quality.
The ultimate limit on the use of PRNGs is that they inevitably have a period of repetition. That is a finite number of random numbers that it will generate until the same sequence of numbers will repeat. If you use n bits for the seed then the longest possible number of iterations until it repeats is 2n. This means that if you use a single byte (8 bits) for your seed you will see a repeating sequence after 256 random numbers have been drawn. That is far too low for most practical purposes. On the other hand if you use a 64 bit value then you will have a bit less than 2 x 1019 numbers before you see the sequence repeat, which is large enough for almost any use that you can think of. Most real implementations of PRNGs use large enough seed values that this isn't a problem in the real world. It is important to remember that repetition of a particular sequence doesn't mean that the RNG has looped and is repeating. You can easily imagine that a PRNG will produce a lot of sequences that go "1,1,0,1,0" in 2 x 1019numbers.
There are a lot of tests for randomness (the popular TestU01 test suite has 160 tests in it's "Big Crush" test), but the most important ones for scientific use (in my opinion at least) are
- Chi-Square test - Make sure that all symbols that the PRNG can produce are produced at the expected rate
- Serial-correlation test - Make sure that the autocorrelation (degree of relatedness between pairs of numbers) is zero. This ensures that you can't predict that you will always get the number 8 in three iterations if you get 3 now
- Spectral test - How densely the numbers generated by the PRNG fill the space of all possible numbers (that is a massive simplification of the spectral test, see here and links for more details)
These three tests are well passed by modern PRNGs so for most non cryptographic (I stress this again!) purposes will be fine. If you are doing cryptography follow the best practices of the cryptographic community. Better yet do not write your own cryptographic code!
The final question is : how do you choose a good seed to start from? That is quite easy for most scientific or technical problems. If you want a random sequence but want to be able to reproduce it reliably you should choose a seed youself by any mechanism that you want, for a good PRNG there isn't a bad seed. If you want it to be random every time you run your code you need some source of entropy to bootstrap the PRNG. The classic bootstrapping entropy is to use the system clock, since the exact time at which you run your problem is probably random. The "better" way is to use one of the system entropy sources such as /dev/random and /dev/urandom on POSIX systems or CryptGenRandom on Windows. These will make use of any hardware RNGs that the system has (where appropriate) and also generates entropy based on other sources of randomness available to the system.
Final note: IT IS VERY IMPORTANT TO RUN YOUR PROBLEM WITH DIFFERENT SEEDS! Unless your result is robust to different random initial conditions it isn't a result, it is an artifact of a particular random sequence that shouldn't priviliged compared to other random sequences.
PRNGs are an efficient way of generating uniformly distributed random numbers, but what if you don't want uniformly distributed random numbers? That will be covered in a later blog post.
Christopher Brady
16 May 2018 14:50
| ![]() Tags: Programming
| Comments (0)
| Report a problem
Tags: Programming
| Comments (0)
| Report a problem
May 02, 2018
Hierarchies of Git(s)
Version Control and Git
Version control of some sort is essential in a software project. Suppose you make a change and your code no longer works - how can you go back? Suppose you find something you don't understand - who made that change? If you publish work using a code, can you recover the exact state at a later time? While carefully maintained records can go a long way, these exact problems led to the development of sophisticated version control systems which could do these things almost automtically. One of the most popular systems in use now is named 'git'.
For a basic rundown of version control, git, and why and how to use it, we have some notes here. This post is a (very brief) introduction to a useful but relatively uncommon feature, git submodules.
The name git, by the way, is no coincidence. It is a handy, pronounceable, 3-letter combination, that wasn't already in use for any Linux utilities, but also a convenient descriptor for the project creator, Linus Torvalds of Linux fame.
Great Fleas have Smaller Fleas
On one occasion we had a request for support in which a user was getting a cryptic error messages about `fatal: bad revision 'HEAD'` when attempting any git commands in any directories. In particular, he was unable to build our code because it used a `git describe` to obtain version information. After a bit of digging, we were able to work out that somewhere in a directory above our source code, he must have run a `git init` command.
This left our git repository in a invalid state and most git commands unusable. The user recalled typing the command, but not where he did it, so first we had to find the bad directory level. Since commands were failing, we could simply work upwards one directory at a time running `git describe` until we instead saw `fatal: Not a git repository (or any of the parent directories)`. A better solution is to use the command `git rev-parse --show-toplevel` which displays the current top-level git repository name.
Running this, it appears he had managed to do this in his `home` directory, leaving any and all git repositories among his files in this state. Thankfully the final remedy is simple: remove the invalid git directory by simply deleting the `.git/` folder at the wrongly initialised level. Much easier than feared!
Submodules
The proper way to have this sort of nested git project is using a relatively uncommon feature called submodules. These are separate git projects which can be imported and used, and are commonly used for deeply embedded library code. A submodule is a repository in its own right and can be checked out alone, and work on it should generally be done separately in this way.
For most people their only encounter with submodules will be the following two commands. When cloning a project that uses them, clone all submodules also using:
git clone --recursive [repo]
When making and removing small, temporary alterations within the submodule, some times when the submodule changes in the repository you cloned from, or any time you see a message like
-Subproject commit abc123xyz +Subproject commit def456uvw
in a git diff, the command:
git submodule update --recursive
will update all submodules to their current versions. The 'recursive' flag ensures all submodules, including any within other submodules, are updated.
But What Actually Are Submodules?
Basically, a submodule is a separate repository, connected to the main project. This connection is via a single commit, and a submodule within a main project is in a detached-head state. As of git 1.8.2 submodules included in a larger project can specify which branch of the submodule project to link to.
For all the gory details of working with submodules, see resources such as
https://www.git-scm.com/docs/gitsubmodules
https://git.wiki.kernel.org/index.php/GitSubmoduleTutorial
and https://blog.github.com/2016-02-01-working-with-submodules/
For now, you can think of them as a way to include 'library' type code which is under active development into several other projects and also allow it to stand alone.
Rescuing a Bad Chain
Sadly it is not particularly difficult to make a small alteration in a submodule (such as temporarily amending a compiler flag) and find yourself with a main repository insisting that there are uncommitted changes in the submodule, or worse, an unexpected detached head somewhere. Don't lose your head over this (sorry). Sometimes the submodule update command is all you need. Other times you will have to reset all the directories. First, commit or stash any changes you want to keep! Then the command
git submodule foreach --recursive git reset --hard
will remove all changes in all submodules, and a final
git submodule update --recursive
should put everything back to normal.
Summary
Git submodules are a powerful, sometimes tricky feature, which basically allow the inclusion of shared code into several other projects while also letting it to stand alone, to be released as a library and/or developed as a separate project. If you encounter submodules it will probably be as simple as somebody's repo needing to be cloned with the --recursive flag. To contribute to the submodule, clone it and only it instead. If you get stuff in your `git status` about changes in a submodule within a larger project try the update command.
Heather Ratcliffe
02 May 2018 11:28
| ![]() Tags: Code Git Programming
| Comments (0)
| Report a problem
Tags: Code Git Programming
| Comments (0)
| Report a problem
April 20, 2018
Proper Planning and Preparation
There is an old, supposedly military adage, which reads
Proper Planning and Preparation Prevents Piss Poor Performance.
This applies to many things, including software development projects. There is also a popular idea known as Hofstadter's Law:
It always takes longer than you expect, even when you take into account Hofstadter's Law.
This is an amusing idea, but is sometimes allowed to apply to real life, which rapidly spirals out of control. There are many reasons a software project keeps taking longer the more you work on it, most of which are best avoided. This post is a brief introduction to how to plan, how to work, and how to keep things on track.
Software for Research
RSE is Research Software Engineering, which can mean many things, but ultimately means we are in the business of writing software used for doing research. Similarly, researchers-who-write-code should be aiming to for the least work which gets them reliable, verifiable, useable code. Note that usable includes being fast enough, and reliable includes doing enough testing.
This makes planning and scheduling essential, to make sure work gets done in time to produce research outputs, but also means it should be lightweight, simple and flexible.
Why Plans Fail
No plan survives contact with the enemy
(A well known paraphrase of a quote by H. von Moltke). Just like Hofstadter's law, one can add the corollary 'even if you include that in the plan'. Knowing the challenges ahead of time lets you plan around them, which gives the vast chance of something from the plan surviving. The following are the commonest sorts of issues to consider.
Shooting in the Dark
It's quite common to start a project not knowing exactly how to do it. This is fine, but has to be allowed for in the plan. For instance, allowing time to write a small test problem using a new library/tool before jumping into the main project, or allowing time at the end to rewrite/refactor (see below). Do not fall victim to the sunk costs fallacy and continue something unpromising just because you have already invested time and effort into it.
Scope Creep
Scope creep is probably the biggest problem many people face with research code. What starts as a simple script turns into a complex behemoth, and never seems to end. A vital part of planning, particularly if you are shooting in the dark, is to decide exactly what the code must do, and once that goal is reached, to stop. This is the perfect point to rejig things, debug well, document, optimise etc, before making a new plan to add all the things you now know you need. Endless rolling feature addition is risky.
Debug Deluge
It isn't uncommon to see a programmer writing pages of code before ever testing if it runs, or even compiles. This goes away with experience, but is often replaced by a related issue, of writing a bunch of stuff and then finding out that it doesn't quite work and has created a debugging nightmare. A better approach is to work in chunks, making each bit work, testing it, and only then integrating it into the whole. This way there's no deluge of debugging to be done, which can take a very long time; only small pieces at a time which are easier to plan for. This is related to the programming style called Test Driven Development (see below).
Premature Optimisation...
...is the root of all evil (Donald Knuth). Until your code works, there is nothing to optimise, as you'd just be doing the wrong thing faster. However, it is important to consider what the code needs to do in the end, and design and plan something that will be fast and efficient enough.
Refactor or Rewrite
Refactoring is rewriting pieces of a code so that the blocks (usually functions) give the same answers but are simpler, faster, more maintainable etc. Rewriting covers more substantial changes, such as changing core data structures or moving from hard-coded input values to a configuration file etc.
Getting Agile
If you have seen any of the Indiana Jones films, you may notice he applies something very like this. Rather than crafting a complex plan and trying to implement it in the face of changing circumstances, he adapts to things as they happen and is never more than a step, or a few steps ahead. This is basically the idea behind the 'Agile Methodology' of software development.
Since clients (or in our case, a research problem) change what they need over time, the idea is to plan only a few weeks ahead, adapting to changing needs as they arise. This is great for commercial development, which is all about happy customers, but does have a few pathologies for research software if done strictly. The main concerns are stopping yourself letting your scope creep out of control, and getting good enough time estimates to be sure you can complete a project, and that it will benefit you.
It's well worth reading a few articles about Agile to see what it's all about, and taking any bits you feel are useful for your own development.
Test Driven Developement (Lite)
'Test-driven-development' (TDD) means writing tests first, and considering a piece of code complete once it passes them, at which point it is done and work should stop. This has plenty of advantages, in particular that you avoid the pitfall of writing the test already knowing how the code works, which often leads to writing a test you know will pass.
The over-literal genie crops up all over the place and something very similar happens when you give clever people a set of rules. For a lot of scientific code, the natural test set is a handful of analytically soluble problems, for which exact answers are known. Using these as the test suite, the obvious, and strictly correct, TDD approach is just to hard-code their solutions. Every test passes, and the code is complete and usually completely useless too.
Rather than strict Test Driven Development, we'd recommend using writing tests for functions before or just after you finish them, making sure they work for all the parameter ranges etc that you need especially things like negative numbers, and then keeping the tests for when or if you change those functions. Rather than running everything every time you make changes you can just run the relevant tests and satisfy yourself that nothing is broken and then focus on integrating pieces together and making sure they all work in combination.
Planning for a Project
Everybody has their own way of planning, and really the only important thing is to do something so that you can estimate how long something will take and keep yourself honest along the way. For small things you only need to take an educated guess how many hours or weeks something will require. For more complex projects you may want to consider some kind of itemised planning process.
This file project_estimatorwexample.pdf is an example of such a planning worksheet, including an example based on my last project. This sheet tries to calculate a time requirement based on some common factors in research code. The multipliers and scalings are only a guess, and the last section adds an arbitrary buffer factor, but this would hopefully provide a starting point for making formal time estimates.
Last Word
This is quite an eclectic post, running through a few bits of useful knowledge that often get left out of programing introductions. The core point is simply
If you fail to plan, you are planning to fail!
Make a plan, stick to it as far as possible, but don't plan so far ahead that you're constantly wasting time re-forming your plans instead of getting work done!
Heather Ratcliffe
20 Apr 2018 13:09
| ![]() Tags: Code Programming
| Comments (0)
| Report a problem
Tags: Code Programming
| Comments (0)
| Report a problem
February 01, 2018
Upcoming training opportunity
February 26-27, University of Leicester. Software Carpentry. A 2-day rapid introduction to basic programming and tools, primarily focussed on programming in Python.
Heather Ratcliffe
01 Feb 2018 14:06
| ![]() Tags: External Programming Training
| Comments (0)
| Report a problem
Tags: External Programming Training
| Comments (0)
| Report a problem
 Loading…
Loading…

