All 2 entries tagged Matlab
View all 7 entries tagged Matlab on Warwick Blogs | View entries tagged Matlab at Technorati | There are no images tagged Matlab on this blog
October 05, 2014
Matlab Log File 'Art'
Sometimes I like to create an image from a dataset, just because. (Previously http://blogs.warwick.ac.uk/mikewillis/entry/useless_visualisation_of/) Also a few weeks ago I was looking at Matlab log files a lot (http://blogs.warwick.ac.uk/mikewillis/entry/fun_with_flexlm/). And thus, this
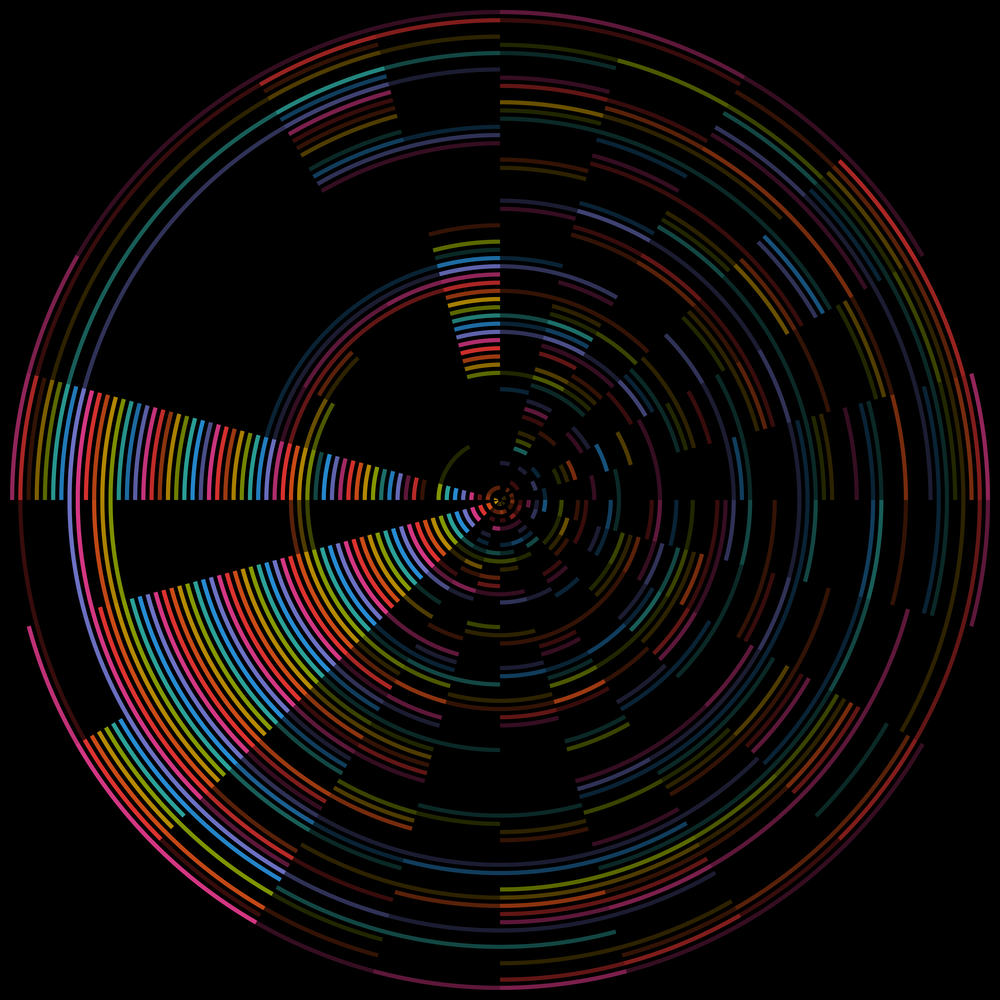
(Click to embiggen.)
It's generated from Matlab license check outs for a single day. The image consists of 60 concentric circles split in to 24 segments. Each circle represents one minute, the innermost circle being 0 and the outermost 59 minutes past the hour. Each segment represents one hour. Midnight is where 12 would be on a clock face, noon is where 6 would be. A coloured segment indicates that a license was checked out during that hour. The distance from the centre represents the minutes past the hour when the license was checked out. Each segment is drawn with an opacity of 25%. The brighter the segment the more licenses checked out, though the brightness tops out at four licenses. (Finer graduations would mean that segments representing a single license would be really faint.) For example, the image below shows from inner to outer:
- 1 license checked out at N minutes past midnight then being checked in sometime between 01:00 and 02:00
- 2 licenses being checked out at N+1 minutes past 01:00 with one checked in again during the same hour and no check in time being found for the other license.
- 4 licenses being checked out N+2 minutes past 02:00 then checked back in again sometime in the same hour (not necessarily at the same time).

There is an element of doubt around tracking when a given license is checked in again. The Matlab license server log does not allocate any sort of identifier to a license check out so it's impossible to definitively identify when it was checked in again. I have taken the check in time to be the first time that a check in by the user@host combination occurs after they checked out a license. A user checking out multiple licenses from a single host could make that assumption incorrect.
The colours are the accent colours of the solarized palette http://ethanschoonover.com/
Here's an image from the same data using colours used by Pirelli to denote the different compounds of their Formula 1 tyres.

This is with the colours of the RAF roundel. (Things which are round…)

I was going to try doing one with University colours. Then I discovered the Corporate Identity part of the University website, which used to provide details of a colour palette for use in things University related, currently only provides details for a single shade of blue.
The images are generated using a bash script and ImageMagick. The script draws up to 5000 segments at a time. Initially it drew one at a time but it's a lot quicker drawing multiple segments at the same time. 5000 seemed like a nice number that didn't trip that error you get when bash command arguments are too long. It's nowhere near 5000 times quicker to draw segments 5000 at a time. This is due, to some degree I don't care enough to work out even roughly, to the temporary images being stored as mpc (http://www.imagemagick.org/Usage/files/#mpc) on tmpfs, thus minimising I/O overheard. (I (mis)use /dev/shm for this sort of thing since it's already there and usually has enough space.) Images are generated at 10000x10000 then shrunk. This is done to remove small unwanted artefacts which sometimes show up between adjacent segments in the same circle. Like this

As that example shows, they don't appear consistently and I'm not sure why they do. I can't make them not occur without leaving gaps. If the images are generated at 1000x1000 the artefacts show up. If the images are generated at 10000x10000 the artefacts show up, but conveniently this detail is lost when the image is shrunk to 1000x1000.
Other examples which I find less aesthetically pleasing than the one linked here can be seen at http://blogs.warwick.ac.uk/mikewillis/gallery/matlab_log_file_art/
 Mike Willis
05 Oct 2014 17:42
|
Mike Willis
05 Oct 2014 17:42
| ![]() Tags: Art Bash Flexlm Imagemagick Matlab
|
Tags: Art Bash Flexlm Imagemagick Matlab
|  Comments (0)
|
Comments (0)
|  Report a problem
Report a problem
 Please wait - comments are loading
Please wait - comments are loading
August 25, 2014
Fun with flexlm log files
All three scripts referred to in this post can be found in Fun scripts for processing flexlm log files and have been tested on Linux, Mac OS X and Solaris.
Edit @ 21/11/2014. If your flexlm file comes from a Windows machine, run it through dos2unix first, otherwise the output will have newlines in places you don't want them.
Edit @ 06/11/2016. Fixed processor count being wrong the the processor model name includes the word "processor". Thanks to Chris Tothill for pointing that out.
I've recently found myself looking at the flexlm log for a Matlab license server a lot. I've been mainly wanting to know two things, when did a given person check out a license and who has checked out licenses between two dates. The format of the flexlm license file makes it quite annoying to answer those questions because the lines for people checking out licenses in and out don't contain date info. All you get is something like this
11:55:52 (MLM) OUT: "MATLAB" ringo@blerg
There are occasional lines in the log that give you the date
18:00:54 (MLM) TIMESTAMP 3/14/2013
So if you want to know the date of a particular entry, you can backtrack from it until you find a TIMESTAMP line. It's cumbersome and annoying and gets more so the busier the license server is. I was dealing with a log file that had grown to over 3million lines covering about 17 months. Sometimes the preceding TIMESTAMP is over 500 lines away. Also the date in the TIMESTAMP lines is in the US format month/date/year, which my brain finds hard to deal with. It's a stupid way to write the date. It's not big endian, it's not little endian, it's just a mess that causes endless grief for people not in the US.
Unable to Google up any such pre-existing thing, I ended up writing a script flexlm_add_dates_to_log to parse the log file and prepend dates to all the lines. (As Google bait I'll also say that it adds the date and that you want to add the date.) The result looks like:
2013-03-18 01:06:12 (MLM) TIMESTAMP 3/18/2013
2013-03-18 01:06:15 (MLM) OUT: "MATLAB" george@blah1
2013-03-18 01:06:15 (MLM) IN: "MAP_Toolbox" ringo@blah2
2013-03-18 01:06:16 (MLM) IN: "MATLAB" john@blah3
2013-03-18 01:06:16 (MLM) OUT: "MAP_Toolbox" paul@blah4
Output is written to stdout, you'll probably want to dump it to a file in a suitable location for later analysis.
Figuring out which date to prepend turned out to be a trickier than it first appeared. At first glance you just go through the file one line at a time and every time you find a TIMESTAMP you write that date to the start of the following lines. But TIMESTAMP lines are written at an intervals of six hours. So you end up with sections of the log that look like this
22:26:18 (lmgrd) TIMESTAMP 5/22/2013
23:19:37 (MLM) OUT: "MATLAB" ringo@blah1
23:21:07 (MLM) OUT: "MAP_Toolbox" john@blah2
23:45:24 (MLM) IN: "MATLAB" paul@blah3
23:45:24 (MLM) IN: "MAP_Toolbox" george@blah4
0:19:37 (MLM) OUT: "MATLAB" ringo@blah1
0:21:07 (MLM) OUT: "MAP_Toolbox" john@blah2
0:45:24 (MLM) IN: "MATLAB" paul@blah3
0:45:24 (MLM) IN: "MAP_Toolbox" george@blah4
4:26:18 (lmgrd) TIMESTAMP 5/23/2013
Well not exactly like that, for one thing MLM also writes TIMESTAMP lines and secondly I've copy/pasted some lines and changed the hour, but it illustrates the problem. The first TIMESTAMP in that example is on the 22nd. So in the above example the 22nd would be prepended to all the IN and OUT lines. But look at the time of the last four IN and OUT lines, they actually happened on the 23rd. The way I dealt with that was to also track the hour. When a TIMESTAMP is found the hour is noted and stored as $hour_last_verified. When an IN or OUT line is encountered, the hour is extracted and if it's less than $hour_last_verified, e.g. $hour_last_verified is 23 and the hour just found is 0, then the date prepended is incremented by a day. (It's actually helpful that the time format used is a half arsed 24 hour clock, half arsed because the hour value isn't padded with a leading zero yet the minutes and seconds are. So you don't have mess around converting 02 in to 2 to do an integer comparison. My script pads the hour value in the ouput for neatness.)
Incrementing the date by a day turned out to be surprisingly problematic too. The script is written in bash, so the obvious way to do something like figure out what the day after a certain date is is to call the date command. This is very easy with GNU date, but sadly Mac OS X and Solaris don't ship with GNU userland and whatever date command they ship with lacks the functionality you'd use with GNU date. I decided I wanted to make life difficult for myself by having the script work on Linux, Mac OS X and Solaris. I then spent far longer than was sensible trying to figure out a single way of doing the date calculation that would work on Linux, Mac OS X and Solaris without resorting to python or perl. I've concluded it's impossible. So the script looks to see if it can find what appears to be GNU date installed somewhere, then the date calculation is done by trying to do it the GNU way then if that fails, doing it another way. (If you want to get GNU userland on Mac OS X, install MacPorts and then install the coreutils package.)
It turned out flexlm_add_dates_to_log can take a while to run if you have a very large file, like the 3million line long one I had. (In my tests anything from 45 minutes upwards.) So I wrote a wrapper script for it flexlm_add_dates_to_log_multi_thread_wrapper which splits the log file in to N chunks, where N is the number of CPU cores, processes them simultaneously then outputs the result to stdout. In my tests it's up to 80% quicker. As with flexlm_add_dates_to_log, this was also more problematic than I initially expected, but I won't bore you with how.
The question of who has checked out license between two dates is actually possible to answer from the raw flexlm log. I figured out how to do it with sed and a regular expression that matched TIMESTAMP lines, but then I negected to save a copy of the regex anywhere and also it required the date to be provided in the US date format. The script I wrote to do it using the output of flexlm_add_dates_to_log is flexlm_checkout_between_dates. It takes input from a file so you'll have to write the output of flexlm_add_dates_to_log to a file first. I didn't bother making flexlm_checkout_between_dates read from stdin because it would be very inefficient to keep running flexlm_add_dates_to_log then piping the output in to flexlm_checkout_between_dates.
Mike Willis
25 Aug 2014 17:11
| ![]() Tags: Date Dates Flexlm Log Maple Matlab
| Comments (0)
| Report a problem
Tags: Date Dates Flexlm Log Maple Matlab
| Comments (0)
| Report a problem

