All 4 entries tagged Tei
View all 5 entries tagged Tei on Warwick Blogs | View entries tagged Tei at Technorati | There are no images tagged Tei on this blog
February 11, 2016
(De)coding Texts – Using the Text Encoding Initiative as a new way to teach the reading of texts
On 3rd March 2016 Alex Peck and Dr Clare Rowan of the Department of Classics and Ancient History will be hosting a two-hour long workshop for postgraduates, academics and teaching staff of the university that will demonstrate how TEI (the Text Encoding Initiative) can be used as an engaging and stimulating method for teaching and developing text-based skills. The workshop will provide a practical demonstration of how TEI can be used within a teaching environment and will encourage participants to reflect on how such a method could be implemented within a variety of academic disciplines.
To provide a flavour of what participants can expect from the workshop and of how TEI can be used in undergraduate teaching, Alex Peck has written a brief summary of the TEI based teaching project (De)Coding Classics that was piloted in the Department of Classics and Ancient History during the 2015/16 academic year.
(De)Coding Classics was a pilot teaching project that aimed to further develop the text-based skills of critical thinking and close reading through the use of computer coding, namely TEI. The project also looked to expose undergraduates to the world of Digital Humanities and to build an awareness of how many of their online resources in the field of Classics and Ancient History are created. This project was inspired by a similar teaching scheme that was pioneered in the UK by Dr Melodee Beals (the of Sheffield Hallam University now of Loughborough University), who had used TEI in her History module as an innovative and engaging method to help her undergraduate students engage effectively in the analysis of primary textual sources.
TEI, or the TExt Encoding Initiative, is the standard recognised means by which digitally annotated versions of texts or text corpora are created. TEi is extremely versatile, providing a highly detailed appendices of 'tags' and 'elements' that can be used to highlight and annotate a vast range of textual features. Its versatility is further demonstrated by the fact that new 'tags' and 'elements' are frequently added to reflect new trends in textual analysis or to expand the range of texts that can be encoded. This versatility renders TEI an effective tool for the teaching of text-based skills.
(De)Coding Classics was implemented in the second-year core module 'The Hellenistic World'. The module cohort was divided into two groups of approximately 35 students and each group was then led through a highly-practical two-hour seminar. The seminars were hosted in R0.39 as this is currently the only computer lab on campus that has Oxygen (the easy-to-use coding software that we had elected ti use in our teaching spaces) installed on 25 computers. The students were first given a brief introduction to TEI, shown how digital editions of texts are created and look like in their coded form, and encouraged to reflect on the similarities between traditional non-digital text annotation and the practice of coding. Following this relatively short introduction, the students were given a practical step-by-step demonstration on how to encode a simple text using TEI. Once the students had been given the basic skills needed to encode texts on their own, the students were individually assigned a text that had been taken from a complex anthology (the Archive of Hor), which they then proceeded to transcribe and code as they had done during the demonstration. They were instructed to identify and thus code the names of people or deities; topographical information; and statements or facts of historical significance. Once the students had identified these key features, they were then instructed to research them and to create a glossary entry for them based on the findings of this research. In order to conduct this research, the students were encouraged to use the wide range of online resources available in the field of Classics and to record these secondary sources using the department's accepted referencing style. A system was devised in order to avoid the possibility of multiple entries on a single topic or feature. Once the students had finished their glossary entries, and were thus armed with enough information to embark on a detailed interpretation of their respective texts, they were instructed to write a brief commentary. The coded text, commentary and glossary entries were then added to a tailor-made database on the module website. This provided them with an interactive finished product of their work.
Although only being a short pilot project that was limited to a single seminar slot, (De)Coding Classics illustrated the effectiveness of a practical digital approach to the teaching of texts. This particular method resulted in a greater engagement on the aprt of the students with regard to the texts they were assigned and thus comprehension of the utility and importance of textual sources for understanding the Hellenistic World. Moreover, the session was able to improve the students' level of digital confidence and competence, a factor that will undoubtedly be increasingly important in the years ahead. There is thus great potential for the incorporation of further elements of computer coding in the teaching and development of traditional textual as well as linguistic skills, and such a practice could become an important complementary toll in linguistic and textual teaching.
 11 Feb 2016 16:42
|
11 Feb 2016 16:42
| ![]() Tags: Digital Humanities Digital Research Technology Tei Text Text Encoding
|
Tags: Digital Humanities Digital Research Technology Tei Text Text Encoding
|  Comments (0)
|
Comments (0)
|  Report a problem
Report a problem
 Please wait - comments are loading
Please wait - comments are loading
October 14, 2015
Summer School Experience: TEI: What? How? Why?
TEI: What? How? Why?
So what is TEI? TEI stands for the Text Encoding Initiative and is a consensus-based means of organising and structuring your (humanities) data for long-term digital preservation. It is well-understood, widely used, and prepares your data for presentation in a variety of digital formats. Originally developed in conjunction with manuscripts but flexible in application it can be used as a means of creating meta-data for an item, ie. title, author, provenance etc., or for transcribing the item itself. The excellent talk I heard at the DHOxSS on this topic was by James Cummings (ITS, Univ. Ox.).
You can tag elements such as <HI>this</HI> to control the presentation of your document on screen, or names such as <name>James Cummings</name> in order to make the document searchable. Another benefit is that compared to other computer languages it is easy to read as a human, and thus easy to work with if it is your first time behind the scenes of a ready-made document. The TEI handbook weighs more than a conference lunch, but one of the most attractive aspects of the language is that if when describing your text you find that what you want to describe isn’t in the handbook (which when you consider how fussy academics are is quite likely, and furthermore is why the handbook is so thick to begin with) you can simply invent your own tags:
<p><l><noun clause><definite article><capital>T</capital>he</definite article> <adjective>key</adjective> <noun>thing</noun></noun clause> <verb clause><unidentified grammatical element>to</unidentified grammatical element> <verb>remember</verb></verb clause><punctuation>.</punctuation></l></p> … is that you don’t have to tag everything! Creating a TEI document is not an end in itself, tempting as this may be to the more <gap/> amongst us. It is a means to preserve and describe your document in order to accomplish specific predefined ends. Are you interested in social awareness of the new world? If so, tag places. Are you interested in the regional creation of manuscripts? If so, tag local spellings. A recent project which has made extensive use of TEI in my field of early modern drama is Richard Brome Online as discussed by Eleanor Lowe (English and Modern Languages, Oxford Brookes) at the DHOxSS. In this resource there are particular tags for speakers, stage directions, proprs, or acts and scenes (TEI privileges sense over physical arrangement of the text in the source, ie. paragraphs over pages). These provide information both for displaying the text online, and making it searchable by the user.
If you’re not creating an online edition, which most of us currently aren’t, it is still helpful to understand TEI when one encounters these texts, as it is useful to understand what choices went in to the creation of the text you’re reading. It is furthermore useful to have some working knowledge of TEI for the small scale preservation of original manuscripts. It allows for accurate representation of the document for perusal after leaving the rare books room. The focus of your transcription might be on text or physical pre<stain “type=coffee”>sentation,</stain>but in either case the key to success in using TEI is consistency.
Clearly the tags I have been using are not necessarily ideal for all projects. Comprehensive guidelines are available at webpage (above). The ElEPHãT project, as discussed by Pip Willcox (Bodleian Libraries, Univ. Ox.), has with the Text Creation Partnership combined data from HathiTrust, ESTC (English Short Title Catalogue) and EEBO (Early English Books Online) in an extensive TEI project. Various transcriptions of the texts that they have worked on are available online at EEBO. Their work can be utilised via basic searching in order to find places or people of interest to your work, or developed by the user in order to conduct more particular research of their own devising. In a workshop session where we were left to play with the TEI documents available from the TCP I suggested that one could devise numerical tagging across their strong collection of alchemical texts in order to investigate the prevalence of sacred numerology in these works. Unfortunately this may have to wait for another day.
In conclusion:
What?
- TEI is a language which can be used to preserve the data and metadata of early manuscripts and texts.
How?
- The text is inputted manually or, if you’re lucky, via OCR, and marked up (tagged) according to a pre-considered range of purposes to which the data is likely to be put.
Why?
- TEI separates the data from the interface and so ensures that the hard work put into digitising the documents won’t be made redundant once the interface becomes obsolete.
- It is flexible and so can be tailored to the needs of any project.
- It is widely understood allowing for sharing of data.
- It can be read by both computers and humans and so is relatively easy to get to grips with.
- It can be used for the smallest and largest of projects.
- Trust me, its fun!
Emil Rybczak (English) Univ. Warwick.
Emil Rybczak
14 Oct 2015 13:00
| ![]() Tags: Bursary Dhoxss15 Tei Text Encoding
| Comments (0)
| Report a problem
Tags: Bursary Dhoxss15 Tei Text Encoding
| Comments (0)
| Report a problem
December 17, 2013
Three Gifts
With a vague excuse involving wise men and gifts, here are some of my recent finds that might be of interest to humanities scholars:
Visualising Historical Networks looks like a taste of how historians might present their analysis in the future . Well worth watching these projects as they develop. (Thanks to Pat Lockley for pointing this out to me). Here's a tiny snippet of a network graph of economists in Cambridge with connections to Keynes: the gephi map is embedded in the page so you can zoom in and out and explore the links between people.
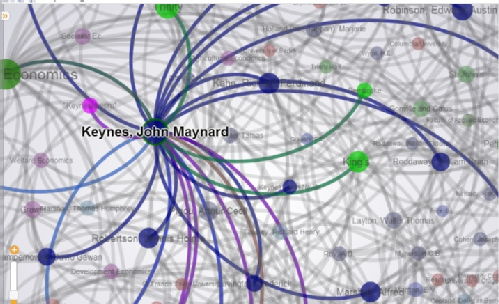
Cambridge Economists: Graphing Ideas
Putting Time in Perspective is an amazing piece of work. It visualises time from the last 24 hours to the whole of human history to geological time, and further. The annotations are thought-provoking too. Here's a taster:
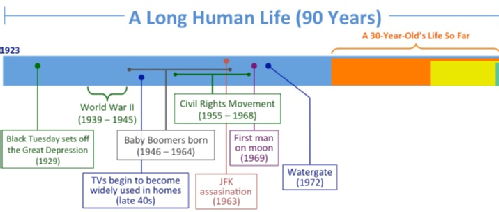
and finally, the big news of the week: Pictures (loads of 'em)
This is HUGE .. over a million images released by the British Library on flickr with a public domain mark which means you can pretty much do anything with them. Put them in blog posts, use them in slides, make art out of them: and there are over a million images taken from the pages of 17th, 18th and 19th century books. A treasue trove! There's a project wiki and one other way to explore them is to browse the Mechanical Curator tumblr. Which I like to imagine looks a bit like some kind of steampunk machine that makes creaky sounds and occasionally whistles as it churns out these amazing images all available for us to reuse ...

Image from "Notes on the Treatment of Gold Ores. Author: O’DRISCOLL, Florence. Page: 214. Year: 1889
Enjoy!
Amber Thomas
17 Dec 2013 20:16
| ![]() Tags: History Tei
| Comments (0)
| Report a problem
Tags: History Tei
| Comments (0)
| Report a problem
September 02, 2013
TEI for Translations of Poetry
My current project has poems originally in Old french, that has been translated into both English and Italian. These are to form a collection on a project website, built using the Sitebuilder system at Warwick, and to allow side-by-side comparison between translations. They are also to be made available as downloadable PDFs and eBooks. The translations are currently being done in a microsoft Word workflow. Here, I outline the decisions and processes made to explore and prototype a TEI workflow for the following benefits:
- Long-term preservation format
- Re-use of single source in multiple formats
- Simplified workflow
- Source presented in multiple ways
- Option to perform textual analysis
docx to TEI
From their current format as docx files, I was aware that underlying them all is accessible xml. From a workflow point of view, being able to programatically extract the poems from docx files and reformat into TEI will make the task much more manageable.
Using oXygen, I was able to open the docx and get to the document.xml which holds the content I'm after. The task here looks like some XPath and XSLT to extract the right information. I have some more learning to traverse the XML structure with XPath to get this working, but in principle I see it is very achievable. In terms of impact to the workflow for the academics involved, is to introduce some strict formatting and structure in the Word documents they are putting the translations into, with visible cues to the underlying structure the XSLT intends to extract in order to be able to write more straight-forward XPath.
This could look like:
- Poem Reference at the top of the document styled as a Title
- Two letter language codes as H1 for each version of these poems
- Between these, A title for the poem as heading 2 (may be first line of poem).
- Then the poem stanzas in paragraph style with line-breaks for individual lines of the stanza.
TEI Document structure
TEI seems the natural choice for encoding these poems, with a straight-forward structure. The complicating factor of this is to consider the translations. A core structural decision is to decide whether each translation is a text in itself, or not, making the file either a corpus or a single text structurally. I opted for the latter, and the following structure:
TEI
teiHeader
text
body
div xml:id= xml:lang
head
lg type=stanza
l
TEI only allows one text and body, so divs are used at a grouping level with @xml:id and @xml:lang to identify the translation, with an additional @corresp linking back to the original translation div from the translations. This is a first implementation, and I am looking to refine this as the project progresses.
XSLT for XHTML
The first output requirement from this project is a webpage. Its desirable for this webpage to lay out different translations next to each other for comparison, and produce line numbers. In order to provide a helpful interface, I began to look at how I could create a more dynamic experience with interchagable tabs by creating a webpage that uses javascript to build a user interface. Using the simplicity of Bootstrap, I was able to create a tabbed interface to switch between languages. Implementing two tabbed interfaces however was proving more tricky, so in this prototype I opted to keep it simple, produce only one, but also to access the URL 'location.search' parameters to be able to request a particular language to be pre-selected in the tabs.
A learning point:
I learned that in-line javascript can syntactically interfere with the XML, and therefore requires putting within <![CDATA[ tags which is accomplished in XSLT with:
<xsl:text disable-output-escaping="yes" >
<![CDATA[
<!--javascript goes here -->
]]>
</xsl:text>
Currently, this prototype is using browser-based XSLT processing to create the output, and these files are hosted on Sitebuilder. To get them displayed in a page therefore requires me to load these with iframes. So I put two iframes side-by-side and pass a parameter to set the default language differently in each to get a configurable UI. Modern browser support for XSLT (not XSLT 2.0) is reportedly good, via w3schools, but I have not tested mine cross-browser yet. Explorations into either cross browser frameworks including javascript implementations, or doing the transform server-side.
I hope to provide a link to this prototype soon.
Steve Ranford
02 Sep 2013 10:21
| ![]() Tags: Tei XML Xsl Xslt
| Comments (0)
| Report a problem
Tags: Tei XML Xsl Xslt
| Comments (0)
| Report a problem
 Loading…
Loading…

