All 2 entries tagged XML
View all 10 entries tagged XML on Warwick Blogs | View entries tagged XML at Technorati | There are no images tagged XML on this blog
October 23, 2013
Tracking the data trail of 'Spatial Humanities'
Following an excellent introduction to GIS and corpus linguistics in the Spatial Humanities project through this week's working lunch (storifyed here) with guest speaker from Lancaster, Ian Gregory. I enjoyed the way he sharing the process of getting from the text to the maps that could tell a visual story. Mapping the Lakes: A Literary GISminisite for project will show you the results.
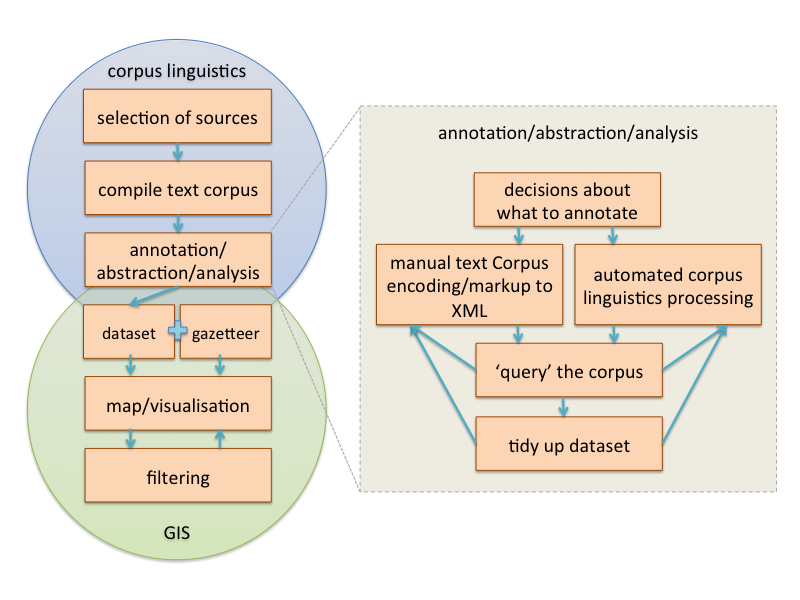
I know many in the room were keen to know what is actually likely to be involved. I felt that a visual recipe or workflow of how you bring the corpus linguistics and geography disciplines together in this way would be helpful in order to see at a simplistic level, what steps are involved. Having not yet done any of this myself, this is an observed workflow from what I understood from Ian's project. Doing this, I felt somewhat uneasy in simplifying what is evidently often an iterative and exploratory process.
Each of the steps identified is in itself a sub-process (or collection of) with decision points and often multiple routes and tools that could be applied. Some of these may be the topic of further exploration. I have pulled out one example with annotation/abstraction/analysis as an example. And this one can indeed be broken down yet further.
 Steve Ranford
23 Oct 2013 11:14
|
Steve Ranford
23 Oct 2013 11:14
| ![]() Tags: Geography Gis History Mapping XML
|
Tags: Geography Gis History Mapping XML
|  Comments (0)
|
Comments (0)
|  Report a problem
Report a problem
 Please wait - comments are loading
Please wait - comments are loading
September 02, 2013
TEI for Translations of Poetry
My current project has poems originally in Old french, that has been translated into both English and Italian. These are to form a collection on a project website, built using the Sitebuilder system at Warwick, and to allow side-by-side comparison between translations. They are also to be made available as downloadable PDFs and eBooks. The translations are currently being done in a microsoft Word workflow. Here, I outline the decisions and processes made to explore and prototype a TEI workflow for the following benefits:
- Long-term preservation format
- Re-use of single source in multiple formats
- Simplified workflow
- Source presented in multiple ways
- Option to perform textual analysis
docx to TEI
From their current format as docx files, I was aware that underlying them all is accessible xml. From a workflow point of view, being able to programatically extract the poems from docx files and reformat into TEI will make the task much more manageable.
Using oXygen, I was able to open the docx and get to the document.xml which holds the content I'm after. The task here looks like some XPath and XSLT to extract the right information. I have some more learning to traverse the XML structure with XPath to get this working, but in principle I see it is very achievable. In terms of impact to the workflow for the academics involved, is to introduce some strict formatting and structure in the Word documents they are putting the translations into, with visible cues to the underlying structure the XSLT intends to extract in order to be able to write more straight-forward XPath.
This could look like:
- Poem Reference at the top of the document styled as a Title
- Two letter language codes as H1 for each version of these poems
- Between these, A title for the poem as heading 2 (may be first line of poem).
- Then the poem stanzas in paragraph style with line-breaks for individual lines of the stanza.
TEI Document structure
TEI seems the natural choice for encoding these poems, with a straight-forward structure. The complicating factor of this is to consider the translations. A core structural decision is to decide whether each translation is a text in itself, or not, making the file either a corpus or a single text structurally. I opted for the latter, and the following structure:
TEI
teiHeader
text
body
div xml:id= xml:lang
head
lg type=stanza
l
TEI only allows one text and body, so divs are used at a grouping level with @xml:id and @xml:lang to identify the translation, with an additional @corresp linking back to the original translation div from the translations. This is a first implementation, and I am looking to refine this as the project progresses.
XSLT for XHTML
The first output requirement from this project is a webpage. Its desirable for this webpage to lay out different translations next to each other for comparison, and produce line numbers. In order to provide a helpful interface, I began to look at how I could create a more dynamic experience with interchagable tabs by creating a webpage that uses javascript to build a user interface. Using the simplicity of Bootstrap, I was able to create a tabbed interface to switch between languages. Implementing two tabbed interfaces however was proving more tricky, so in this prototype I opted to keep it simple, produce only one, but also to access the URL 'location.search' parameters to be able to request a particular language to be pre-selected in the tabs.
A learning point:
I learned that in-line javascript can syntactically interfere with the XML, and therefore requires putting within <![CDATA[ tags which is accomplished in XSLT with:
<xsl:text disable-output-escaping="yes" >
<![CDATA[
<!--javascript goes here -->
]]>
</xsl:text>
Currently, this prototype is using browser-based XSLT processing to create the output, and these files are hosted on Sitebuilder. To get them displayed in a page therefore requires me to load these with iframes. So I put two iframes side-by-side and pass a parameter to set the default language differently in each to get a configurable UI. Modern browser support for XSLT (not XSLT 2.0) is reportedly good, via w3schools, but I have not tested mine cross-browser yet. Explorations into either cross browser frameworks including javascript implementations, or doing the transform server-side.
I hope to provide a link to this prototype soon.
Steve Ranford
02 Sep 2013 10:21
| ![]() Tags: Tei XML Xsl Xslt
| Comments (0)
| Report a problem
Tags: Tei XML Xsl Xslt
| Comments (0)
| Report a problem
 Loading…
Loading…

