The eduWOSM for outreach
On Wednesday we took our eduWOSMs to a Science Gala. The eduWOSM is a high-end, low-cost microscope based on the WOSM (Warwick Open Source Microscope) developed at Warwick Medical School.
History of the WOSM
The WOSM was the brainchild of Nick Carter and Rob Cross. They envisaged a monolithic, highly-stable microscope which would be able to perform experiments that are very sensitive to drift such as optical trapping force measurements and single-molecule localisation experiments (the WOSM can achieve STORM images with 10-20 nm resolution with no drift correction!). As suggested in the name, the WOSM is open source and all the information required to produce your own WOSM is available online at wosmic.org. This information includes CAD files for machining and 3D printing parts as well as controller and software design.
From WOSM to eduWOSM
Last year, Rob approached me with an idea for the new undergraduate course he was developing, due to start autumn 2020. The Hooke integrated science course is designed to teach students in an interdisciplinary and highly interactive manner. The program consists of a series of short courses covering various aspects of biomedical science where students are expected to get hands-on with their own sample prep, data acquisition and processing. A cornerstone of this course is that students should have easy access to high-end, research-level microscopes, no mean feat when a typical research microscope costs around £300k (even a fully-spec’d WOSM might cost around £100k).
Rob proposed that we could take the basic design of the WOSM and adjust the components to significantly reduce the price while maintaining as much sensitivity, specificity and functionality as possible. We could then build multiple systems and students would have a group of microscopes they could call their own, to use and adapt as they desired. The task of developing the eduWOSM was taken up by Doug Martin, with help from Nick he was able to reduce the cost down to under 10k per system. Inspired by the eduSPIM, the system was named the eduWOSM. Purchasing and building for the rest of the required systems for autumn is in progress with a plan for one eduWOSM per two students.
eduWOSM for outreach
We also realised that the eduWOSMs would work well for taking to science outreach events; they are sturdy, compact and robust, perfect for letting anybody take control. They are also LED based so there are no laser safety issues to worry about and their modular nature means we can use them to teach about aspects of microscopy as well as biomedicine. Crucially, the eduWOSM differs from the usual microscopes used for outreach by its high magnification and epi-fluorescence functionality, capable of resolving sub-cellular details such as microtubules.
The first opportunity that presented itself was the XMaS Science Gala, held at Warwick. The aim was to have three eduWOSMs that would be used to show three different samples, representing the “Inner Space” of cells.

Time and skill constraints meant we only ended up with two eduWOSMs but I think for a first time this was probably beneficial. We tried to procure several different samples and were surprised to find that one of the ones that worked best was actually live mammalian (RPE) cells seeded on a glass-bottomed dish, stained with a far-red tubulin dye (SiR-tubulin) and kept in CO2 independent media - all set-up by Muriel Erent. By the end of the 3.5 hours at room temperature there was no obvious detachment or rounding up of cells – we weren’t able to witness any cells progressing through division though, even though we were able to identify many cells in the process of dividing. The other sample we used was a pre-stained slide with four fluorophores, which highlighted the multi-colour abilities of the eduWOSM, visitors were encouraged to try to find dividing cells.
Summary of the Science Gala
Overall I think the first outing of the eduWOSMs at the Science Gala went well. Set-up and selecting suitable samples and finding focus took a bit longer than anticipated and we overran into the start of the event but after that there really weren’t any major issues. People were enthused about the prospect of being able to see living cells and frequently people would come over to ask what the “galaxy” was.
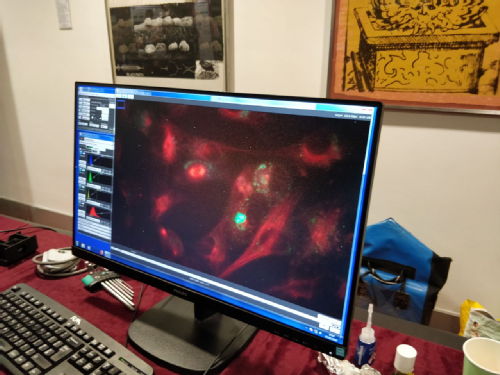
In my experience, the eduWOSMs worked better for older children, who already have met the concept of cells and have used basic microscopes, and adults, who can appreciate the merit of developing a “low-cost” microscope and the potential for education, outreach and low-income communities.
Now we have two eduWOSMs up and running, attending future outreach events should be trivial. I would like to work a bit more on the samples and sample prep, it would be great to have something more dynamic like crawling dictyostelium or swimming algae – two samples we tried to implement but weren’t able to perfect in time. I think in the event of having more eduWOSMs for the next event, it would be good to work on having the systems usable and understandable even when there isn’t a person immediately available to explain what the system is and how to use it. The eduSPIM has an excellent implementation, where you can access information about the system/sample from the (friendly) user interface and the system defaults to a previously generated image in the event of an error.
 Claire Mitchell
10 Feb 2020 10:51
|
Claire Mitchell
10 Feb 2020 10:51
|  Comments (0)
|
Comments (0)
|  Report a problem
Report a problem
 Please wait - comments are loading
Please wait - comments are loading